Python, Parquets & Opendata (parte 2
Uno studio sugli opendata del Fondo di Garanzia, convertiti in file parquet per una maggiore efficienza. L’obiettivo è determinare la distribuzione delle imprese per numero di comuni coinvolti negli…
1 opendata del Fondo di Garanzia, convertiti in file parquet per una maggiore efficienza
L’obiettivo è determinare la distribuzione delle imprese per numero di comuni coinvolti negli investimenti agevolati, utilizzando il codice fiscale anonimizzato come identificativo univoco dell’impresa.
L’analisi prevede il raggruppamento per codice fiscale e comune, e la successiva creazione di un dataframe che riporta il numero di comuni per ogni impresa.
Infine, viene evidenziata la distribuzione fortemente sbilanciata, con la stragrande maggioranza delle imprese (ditte individuali) presente in un solo comune e un’unica impresa presente in ben 16 comuni, richiedendo l’uso di una scala logaritmica per la rappresentazione grafica dei risultati.

www.fondidigaranzia.it
Nella parte uno avevamo visto come trasformare i file CSV del Fondo di Garanzia #FdG in file parquet.
La trasformazione è utile per essere molto più veloci nelle analisi rispetto ad utilizzare file CSV che tra l’altro occupano molto più spazio.
Python permette di utilizzare x file parquet o in altro formato come fosse un database: posso fare quindi qualsiasi analisi interrogando 1 o più file che ho precedentemente raccolto in un’apposita cartella.
dir /o-n /b *.parquetFdG_2024-M11.parquet
FdG_2024-M10.parquet
FdG_2024-M09.parquet
FdG_2024-M08.parquet
FdG_2024-M07.parquet
FdG_2024-M06.parquet
FdG_2024-M05.parquet
FdG_2024-M04.parquet
FdG_2024-M03.parquet
FdG_2024-M02.parquet
FdG_2024-M01.parquet
FdG_2023.parquet
FdG_2022.parquet
FdG_2021.parquet
FdG_2020.parquet
FdG_2019.parquet
FdG_2018-4.parquet
FdG_2018-3.parquet
FdG_2018-2.parquet
FdG_2018-1.parquet
FdG_2017-4.parquet
FdG_2017-3.parquet
FdG_2017-2.parquet
FdG_2017-1.parquet
FdG_2016-4.parquet
FdG_2016-3.parquet
FdG_2016-2.parquet
FdG_2016-1.parquet
FdG_2015-4.parquet
FdG_2015-3.parquet
FdG_2015-2.parquet
FdG_2015-1.parquet
FdG_2014-4.parquet
FdG_2014-3.parquet
FdG_2014-2.parquet
FdG_2014-1.parquet
FdG_2013-4.parquet
FdG_2013-3.parquet
FdG_2013-2.parquet
FdG_2013-1.parquet
FdG_2012-4.parquet
FdG_2012-3.parquet
FdG_2012-2.parquetIl #FdG inserisce negli #opendata il comune dell’impresa che ha ottenuto l’agevolazione.
Il Comune non è il comune sede legale dell’impresa, ma è il comune al quale durante l’istruttoria è stato attribuito l’aiuto di stato.
Potremmo quindi avere imprese che hanno più di un comune in funzione degli investimenti che hanno fatto nel tempo e che sono stati supportati dal #FdG. In questo studio voglio vedere la distribuzione delle imprese per numero di comuni.
Dopo aver importato le librerie, verifico quanti dati ho a disposizione
import pyarrow.parquet as pq
import pandas as pd
import duckdb
import os
con = duckdb.connect()
con.execute("PRAGMA threads=2")
con.execute("PRAGMA enable_object_cache") os.chdir('D:/duckdb/files/FdG/')Oltre 3.900.000 agevolazioni per c.a 1.700.000 imprese.
con.execute("SELECT count(*) FROM '*.parquet';").df()count_star()
0 3994883con.execute("SELECT count(distinct(CF)) FROM '*.parquet';").df() count(DISTINCT CF)
0 1680598Per le analisi utilizzerò il codice fiscale e non la ragione sociale perché quest’ultima a volte viene scritta in maniera differente, mentre il codice fiscale è univoco.
1.1 I codici fiscali delle imprese sono dati sensibili?
Il codice fiscale di un’impresa è considerato un dato personale, ma non rientra nella categoria dei dati sensibili.
Secondo il Regolamento Generale sulla Protezione dei Dati #GDPR , i dati personali sono informazioni che identificano o rendono identificabile una persona fisica, come il nome, l’indirizzo o il codice fiscale.
I dati sensibili, invece, includono informazioni che rivelano l’origine razziale o etnica, le opinioni politiche, le convinzioni religiose o filosofiche, l’appartenenza sindacale, dati genetici, dati biometrici, dati relativi alla salute o alla vita sessuale o all’orientamento sessuale di una persona .
È importante notare che il codice fiscale di un’impresa, essendo associato a una persona giuridica, non è soggetto alle stesse tutele previste per i dati personali delle persone fisiche. Tuttavia, l’utilizzo del codice fiscale deve avvenire nel rispetto delle normative vigenti in materia di protezione dei dati.
Deve essere quindi posta particolare attenzione nel caso delle ditte individuali dove il codice fiscale richiama luogo e data di nascita del soggetto. Qui sotto, ad esempio, i due ipotetici Rossi e Bianchi sono entrambi nati a Roma (H501) ma nel 1985 il primo (85) e nel 1975 (75) il secondo (il primo aprile, per la precisione)
data = {'Nome': ['Mario Rossi', 'Luigi Bianchi'],
'Codice Fiscale': ['RSSMRA85M01H501Z', 'BNCGLG75D01H501Z']}
df = pd.DataFrame(data)Hashlib permette di anonimizzare i dati in un DataFrame, ad esempio, sostituendoli con hash univoci o mascherandoli parzialmente.
hashlib.sha256(codice_fiscale.encode()).hexdigest()
def mask_code(codice_fiscale):
return codice_fiscale[:3] + '*' * 8 + codice_fiscale[-3:]
df['Codice Fiscale Mascherato'] = df['Codice Fiscale'].apply(mask_code)Per evitare errori, anonimizzerò completamente, e non parzialmente, i codici fiscali
import hashlibdef hash_code(codice_fiscale):
return hashlib.sha256(codice_fiscale.encode()).hexdigest()df['Codice Fiscale Anonimizzato'] = df['CF'].apply(hash_code)
df.drop(['CF'], axis=1)
Alcune informazioni (righe) potrebbero essere escluse dall’analisi, ad esempio perchè legate a moratorie e quindi a preesistenti finanziamenti. In questa analisi però sapere che un’impresa ha avuto un finanziamento per un investimento su Roma e successivamente una moratoria, non incide.
Per prima cosa raggruppo le imprese per codice fiscale (anonimizzato) e per comune.
Potrò quindi avere il un’impresa Alfa srl che ha uno o più comuni.
result_df = df.groupby('Codice Fiscale Anonimizzato')['comune'].apply(lambda x: '|'.join(x)).reset_index()
result_df.columns = ['Codice Fiscale Anonimizzato', 'comuni_concatenati'] Per comodità realizzo un nuovo data frame nel quale riporto univocamente i codici fiscali (anonimizzati) e in una seconda colonna la serie di uno o più comuni separati da un pipe.
Otterrò quindi due colonne: nella seconda colonna potrà essere presente o un solo comune o più comuni.
filtered_df = result_df[result_df['comuni_concatenati'].str.contains('|', regex=False)]filtered_df.head()
Per vedere quale codice fiscale ha più comuni in assoluto, faccio dei tentativi andando a filtrare il data frame.
filtered_df[filtered_df['comuni_concatenati'].str.count('\|') >= 15]
Realizzo adesso un altro dataframe nel quale inserisco pure il numero di comuni che sono presenti nella seconda colonna raggruppati per ogni codice fiscale (anonimizzato) e vado ad ordinarli in modo decrescente in maniera che troverò alla prima riga il codice fiscale che ha più comuni presenti.
cf_count_df = result_df.copy()
cf_count_df['num_comuni'] = cf_count_df['comuni_concatenati'].str.count('\|') + 1
cf_count_sorted = cf_count_df.sort_values(by='num_comuni', ascending=False)print(cf_count_sorted)Verifico i primi 10 codici fiscali (anonimizzati) e i relativi comuni.
pd.set_option('display.max_colwidth', 500)
cf_count_sorted.head(10)
Voglio ora sapere quanti codici fiscali hanno uno o più comuni.
cf_count_df = result_df.copy()
cf_count_df['num_comuni'] = cf_count_df['comuni_concatenati'].str.count('\|') + 1
cf_count_distribution = cf_count_df['num_comuni'].value_counts().sort_index(ascending=False)
distribution_df = cf_count_distribution.reset_index(name="count").rename(columns={"index": "num_comuni"})print(distribution_df) num_comuni count
0 16 1
1 14 1
2 12 2
3 10 2
4 9 6
5 8 6
6 7 15
7 6 46
8 5 222
9 4 1139
10 3 8761
11 2 91515
12 1 1578882Come posso vedere, un solo codice fiscale (anonimizzato) è presente in 16 comuni, mentre oltre 1.700.000 codici fiscali sono presenti in un solo comune.
1.2 Datavisualization
Passo ora alla rappresentazione di quest’ultima tabella di raggruppamento, ma devo utilizzare nella colonna delle ordinate la scala logaritmica in quanto il i codici fiscali con un solo comune sono eccessivi rispetto all’unico codice fiscale con 16 comuni.
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 5))
ax = cf_count_df['num_comuni'].value_counts().sort_index(ascending=False).plot(
kind='bar',
title='Distribution of CF by Number of Associated "Comuni" (Log Scale)',
xlabel='Number of Associated Comuni',
ylabel='Frequency (Log Scale)',
rot=0,
log=True
)
for p in ax.patches:
height = p.get_height()
ax.annotate(f'{int(height)}',
(p.get_x() + p.get_width() / 2., height * 1.1),
ha='center', va='bottom', fontsize=10)plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()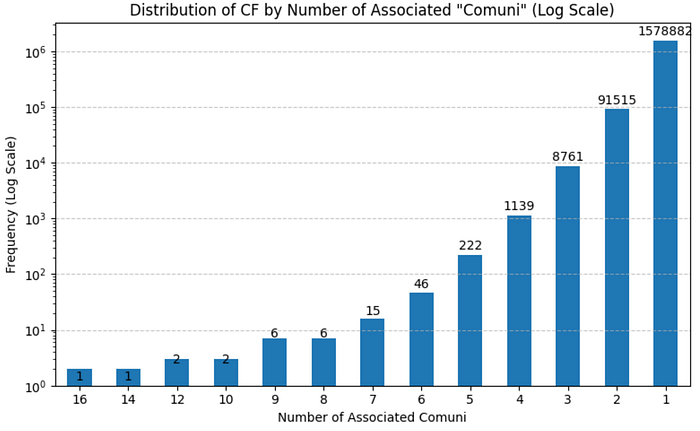
Mi raccomando: ho altri approfondimenti da condividere. Metti like!