import pandas as pd
import os
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
pd.set_option('display.float_format', lambda x: '%.2f' % x)Bonus colonnine domestiche
Python applicato a dati pubblicati online
Agevolazioni
Python
Opendata
MIMIT

1 obiettivi dello studio
- estrazione dati da PDF
- elaborazione grandi file #opendata
- gestione dati geografici (#shapefile)
Contributo a privati e condomini per l’acquisto e l’installazione di infrastrutture per la ricarica dei veicoli alimentati ad energia elettrica
Analisi realizzata con #opendata di MIMIT, ISTAT e Opencup

Il bonus colonnine domestiche è un contributo pari all’80% del prezzo di acquisto e posa delle infrastrutture per la ricarica dei veicoli alimentati ad energia elettrica (come ad esempio colonnine o wall box).
Il limite massimo del contributo è di 1.500 euro per gli utenti privati e fino a 8.000 euro in caso di installazione sulle parti comuni degli edifici condominiali.
Possono beneficiare del contributo le persone fisiche residenti in Italia e i condomìni.
Le risorse a disposizione sono pari a:
- 40 milioni per 2022
- 40 milioni per 2023
- 20 milioni per 2024
| file | numeri | righe |
|---|---|---|
| Allegato_A_Decreto_di_concessione_annualita_2022_bcd.pdf | 561 | 545 |
| Allegato_Decreto_di_concessione_annualità_2023.pdf | 4992 | 4901 |
| Allegato_A_Decreto_di_concessione_nuova_apertura_2023.pdf | 939 | 939 |
| Allegato_A_EM_Decreto_di_concessione_annualita_2024.pdf | 11485 | 11485 |
2 Analisi
2.1 Spese ad oggi ammesse e contributi complessivi concessi
os.chdir('D:\\files\\csv\\Colonnine_elettriche')
date_column = ['Data e ora presentazione domanda']
combined_df = pd.read_csv('combined.csv', parse_dates=date_column, dayfirst=False)
combined_df[['Spese Ammesse (€)','Contributo Concesso (€)']].sum()Spese Ammesse (€) 30368778.47
Contributo Concesso (€) 21095793.24
dtype: float64combined_df.describe()| Unnamed: 0 | N. | Data e ora presentazione domanda | Spese Ammesse (€) | Contributo Concesso (€) | |
|---|---|---|---|---|---|
| count | 17951.00 | 17951.00 | 17951 | 17951.00 | 17951.00 |
| mean | 8975.00 | 3735.90 | 2024-05-25 20:51:53.760013568 | 1691.76 | 1175.19 |
| min | 0.00 | 1.00 | 2023-10-19 10:10:05 | 120.00 | 96.00 |
| 25% | 4487.50 | 130.50 | 2023-11-21 19:45:54.500000 | 1222.45 | 977.96 |
| 50% | 8975.00 | 2509.00 | 2024-07-09 19:55:35 | 1500.00 | 1200.00 |
| 75% | 13462.50 | 6997.50 | 2024-09-24 10:50:55 | 1800.00 | 1440.00 |
| max | 17950.00 | 11485.00 | 2024-11-22 10:58:59 | 1664545.00 | 8000.00 |
| std | 5182.15 | 3770.14 | NaN | 12470.89 | 403.01 |
2.2 Boxplot contributi concessi
# Rimuovi eventuali simboli di valuta e converti in numerico
combined_df['Contributo Concesso (€)'] = combined_df['Contributo Concesso (€)'].replace('[€,]', '', regex=True).astype(float)
# Rimuovi eventuali valori NaN
combined_df_clean = combined_df.dropna(subset=['Contributo Concesso (€)'])
# Genera il boxplot
plt.figure(figsize=(10, 6))
combined_df_clean['Contributo Concesso (€)'].plot(kind='box')
plt.title('Boxplot dei Contributi Concessi (€)', fontsize=14)
plt.ylabel('Contributi Concessi (€)', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.show()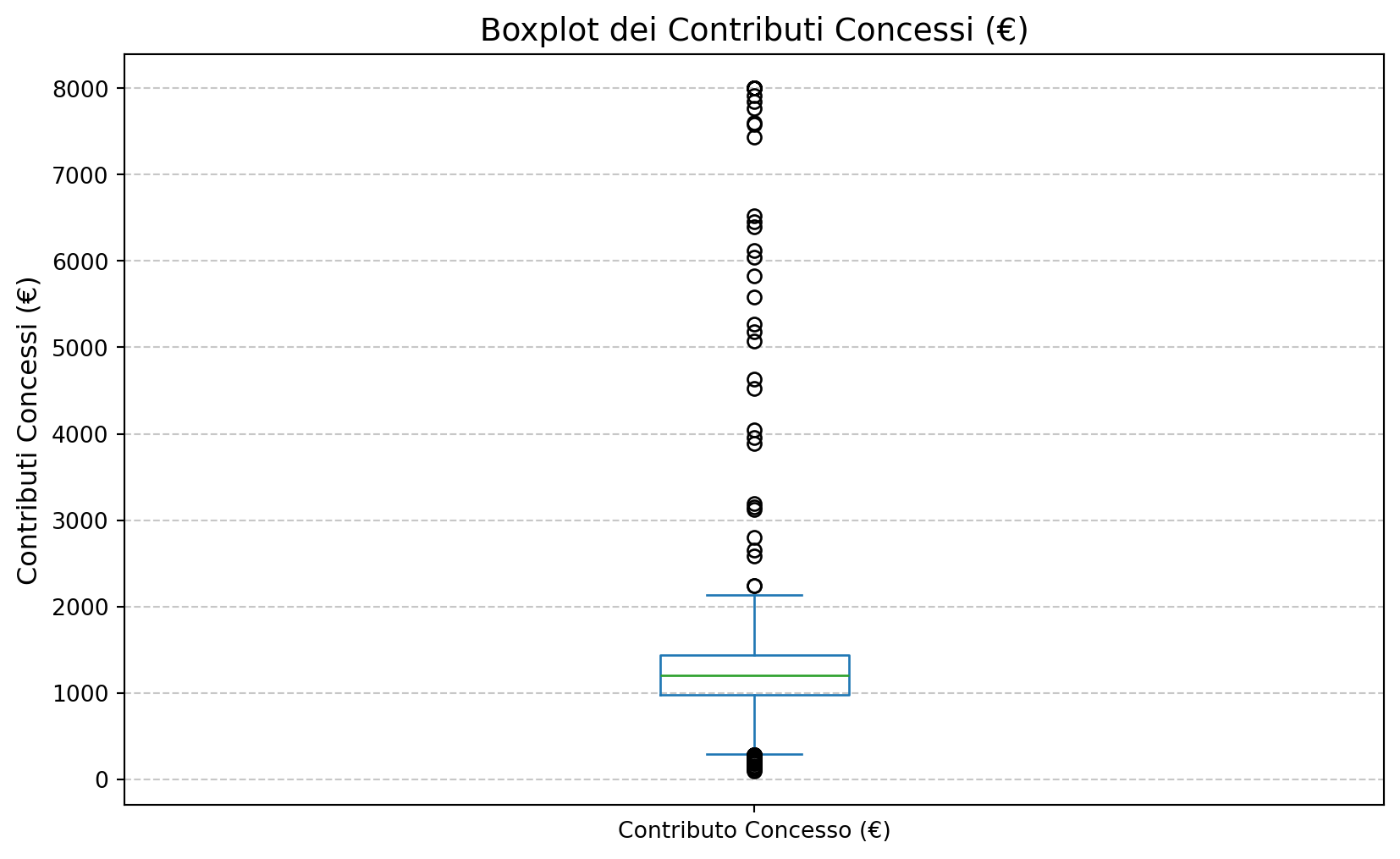
2.3 Histplot
# Funzione per generare il grafico e calcolare i dati dinamicamente
def plot_histogram_with_bins(data, column, bins=30):
# Rimuovi eventuali simboli di valuta e converti in numerico
data[column] = data[column].replace('[€,]', '', regex=True).astype(float)
data_clean = data.dropna(subset=[column])
# Calcola l'istogramma con il numero di bin specificato
counts, bin_edges = np.histogram(data_clean[column], bins=bins)
# Trova il bin con il conteggio maggiore
max_bin_index = counts.argmax()
max_bin_range = (bin_edges[max_bin_index], bin_edges[max_bin_index + 1])
max_bin_center = (max_bin_range[0] + max_bin_range[1]) / 2
# Stampa i risultati
print(f"Numero di bin: {bins}")
print(f"Il bin con il conteggio massimo è tra {max_bin_range[0]:,.2f} e {max_bin_range[1]:,.2f}.")
print(f"Il valore centrale di questo bin è: {max_bin_center:,.2f}.")
print(f"Il conteggio massimo è di {counts[max_bin_index]}.")
# Genera l'istogramma
plt.figure(figsize=(10, 6))
sns.histplot(data=data_clean, x=column, kde=True, bins=bins)
plt.title(f'Distribuzione di {column} - {bins} Bin', fontsize=14)
plt.xlabel(column, fontsize=12)
plt.ylabel('Frequenza', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7)
# Evidenzia il bin con il conteggio maggiore
plt.axvspan(max_bin_range[0], max_bin_range[1], color='orange', alpha=0.3, label='Bin con conteggio massimo')
plt.axvline(max_bin_center, color='red', linestyle='--', label=f'Valore centrale: {max_bin_center:,.2f}')
plt.legend()
plt.show()
# Esempio di utilizzo
plot_histogram_with_bins(combined_df, 'Contributo Concesso (€)', bins=50)Numero di bin: 50
Il bin con il conteggio massimo è tra 1,360.64 e 1,518.72.
Il valore centrale di questo bin è: 1,439.68.
Il conteggio massimo è di 5563.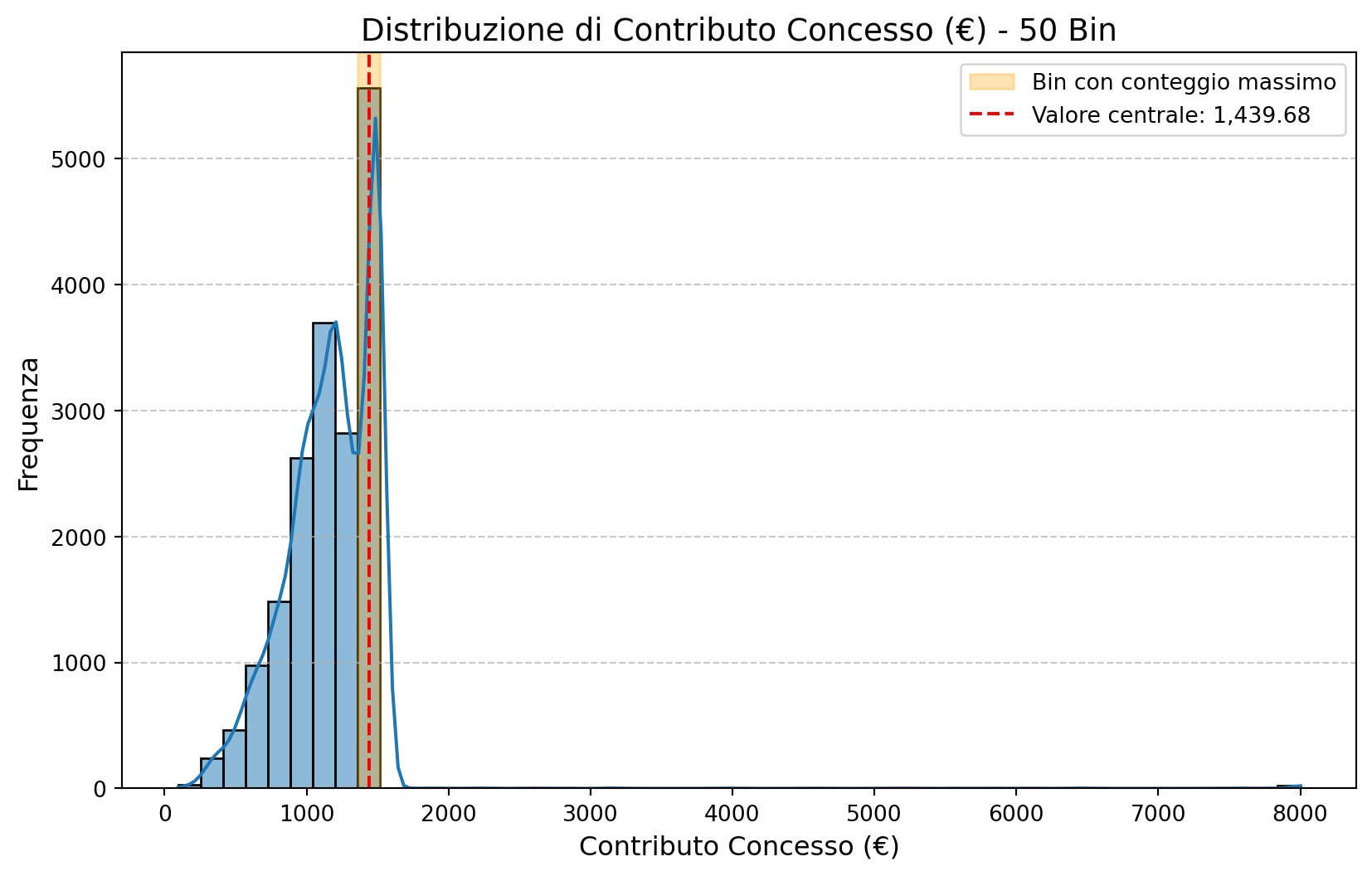
2.4 merge con Opencup localizzazione
import os
os.chdir('D:/duckdb/files/Opencup')
import duckdb
conn = duckdb.connect()
conn.execute("CREATE TABLE OpenCup_Localizzazione AS SELECT * FROM 'OpenCup_Localizzazione.parquet';")
conn.register('df2', combined_df)
query = """SELECT a.*, b.* FROM df2 a LEFT JOIN OpenCup_Localizzazione b ON a.CUP = b.CUP ;"""
result2 = conn.execute(query).df()
result2 = result2[['CUP', 'CODICE_REGIONE','REGIONE','SIGLA_PROVINCIA', 'COMUNE', 'N.',
'ID Domanda', 'Data e ora presentazione domanda',
'Soggetto richiedente', 'Codice fiscale', 'Spese Ammesse (€)',
'Contributo Concesso (€)']]
result2.head()| CUP | CODICE_REGIONE | REGIONE | SIGLA_PROVINCIA | COMUNE | N. | ID Domanda | Data e ora presentazione domanda | Soggetto richiedente | Codice fiscale | Spese Ammesse (€) | Contributo Concesso (€) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | C42E23004680008 | 3 | LOMBARDIA | MB | DESIO | 2.17 | BCDS2300002234 | 2023-11-14 15:56:45 | M... C... G... | G.......................794R | 2150.00 | 1500.00 |
| 1 | B42E24043420008 | 12 | LAZIO | FR | ATINA | 2982.00 | BCDBS2400003002 | 2024-07-11 15:45:00 | F... S... | S...............838C | 1727.27 | 1381.82 |
| 2 | C42E23004900008 | 3 | LOMBARDIA | MI | MILANO | 2.69 | BCDS2300002775 | 2023-11-16 21:03:10 | L... P... | P.......................205F | 2000.00 | 1500.00 |
| 3 | B42E24047920008 | 3 | LOMBARDIA | MI | MILANO | 6531.00 | BCDBS2400006566 | 2024-09-12 08:36:09 | S... B... | B...............205T | 3870.09 | 1500.00 |
| 4 | B92E24043830008 | 6 | FRIULI-VENEZIA GIULIA | UD | MANZANO | 2318.00 | BCDBS2400002337 | 2024-07-09 12:09:56 | G... S... | S...............758D | 2100.00 | 1500.00 |
2.4.1 per regione
result2['REGIONE'].count()17951result2_grouped = result2.groupby(['REGIONE', 'CODICE_REGIONE']).size().reset_index(name='COUNT') # Raggruppa per REGIONE e seleziona CODICE_REGIONE
result2_grouped_sorted = result2_grouped.sort_values(by='CODICE_REGIONE', ascending=True) # Ordina per CODICE_REGIONE (non per COUNT)
print(result2_grouped_sorted[['REGIONE','COUNT']]) # Mostra il risultato REGIONE COUNT
11 PIEMONTE 1261
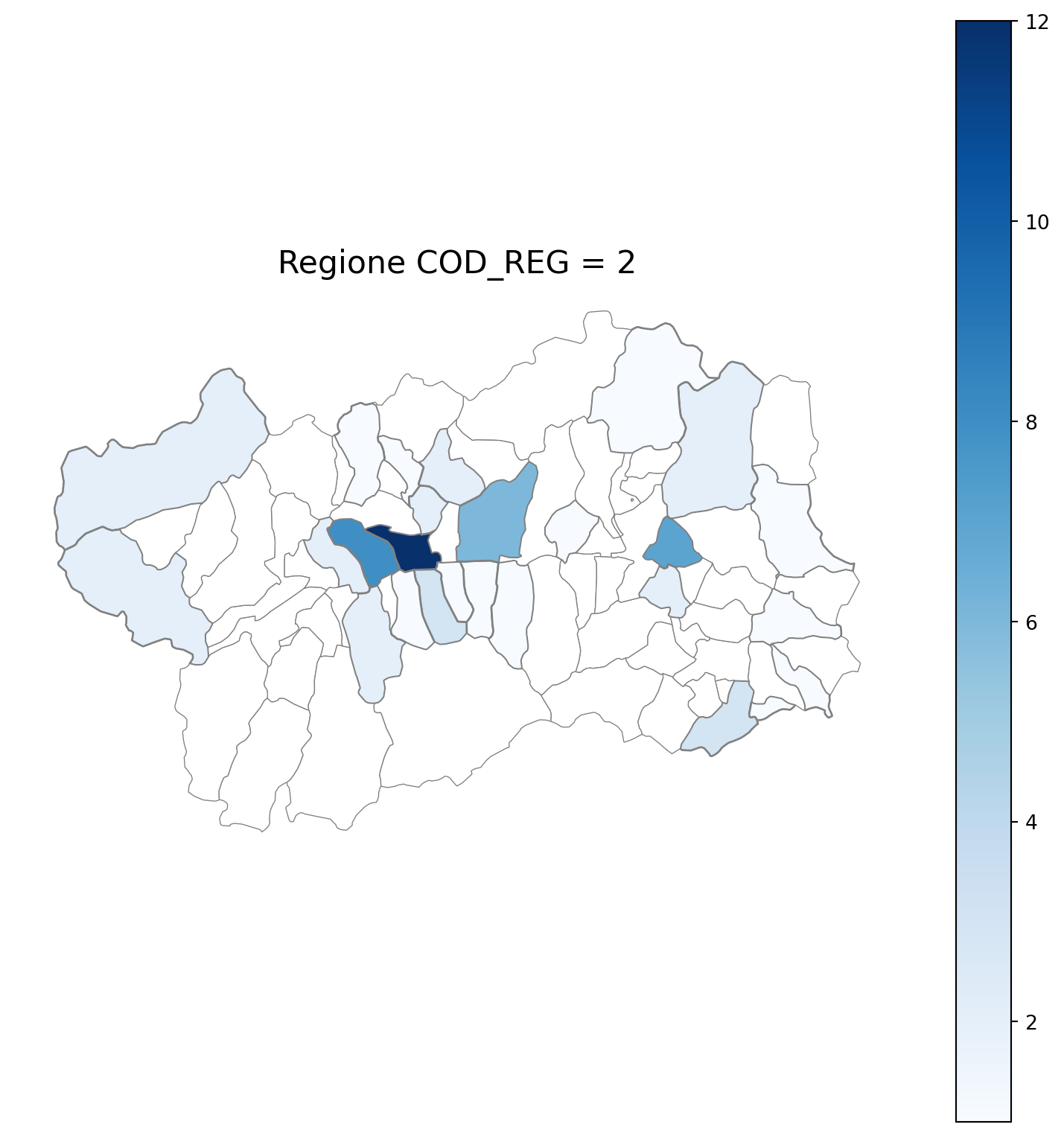
18 VALLE D'AOSTA 77
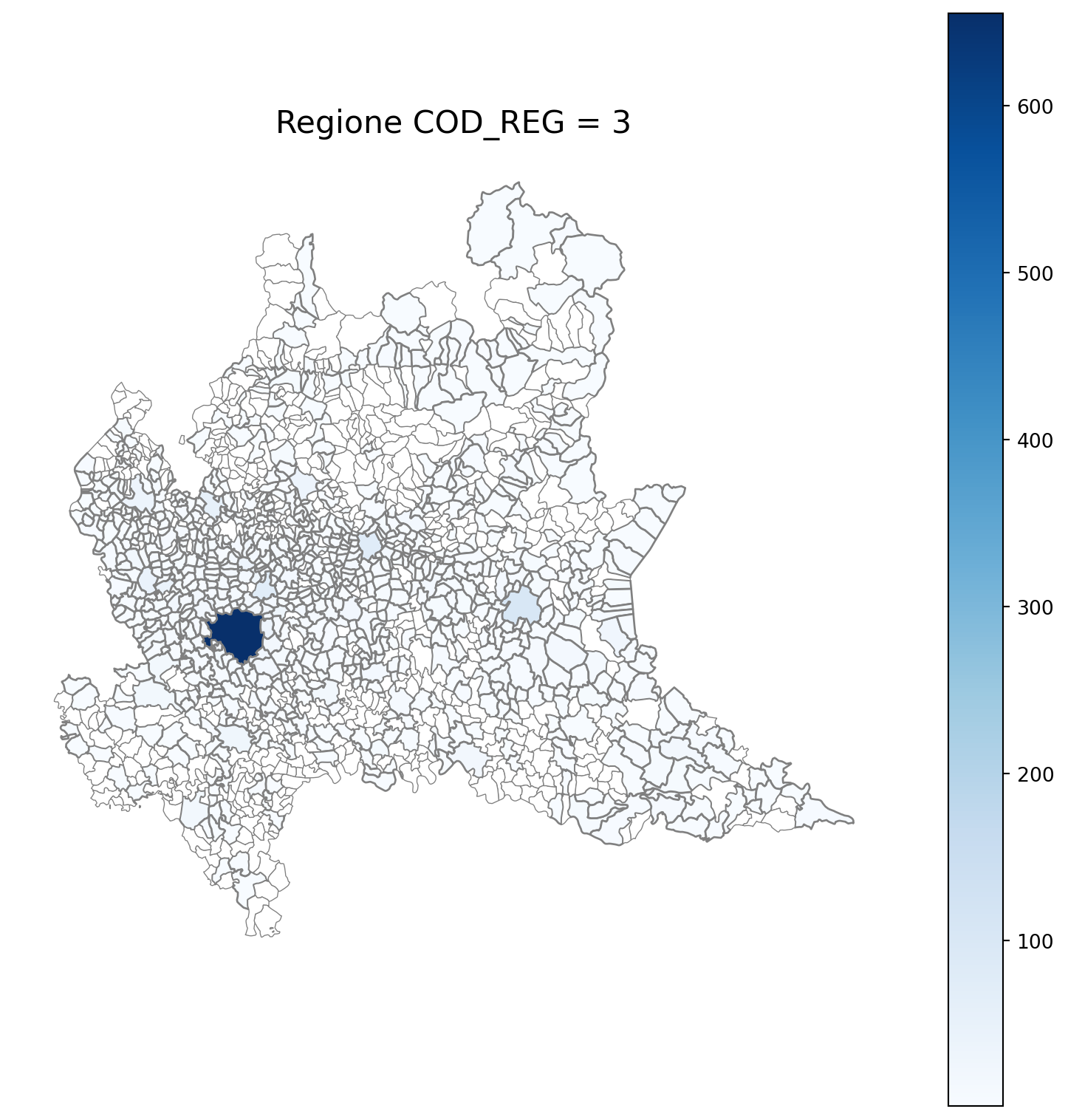
8 LOMBARDIA 4868
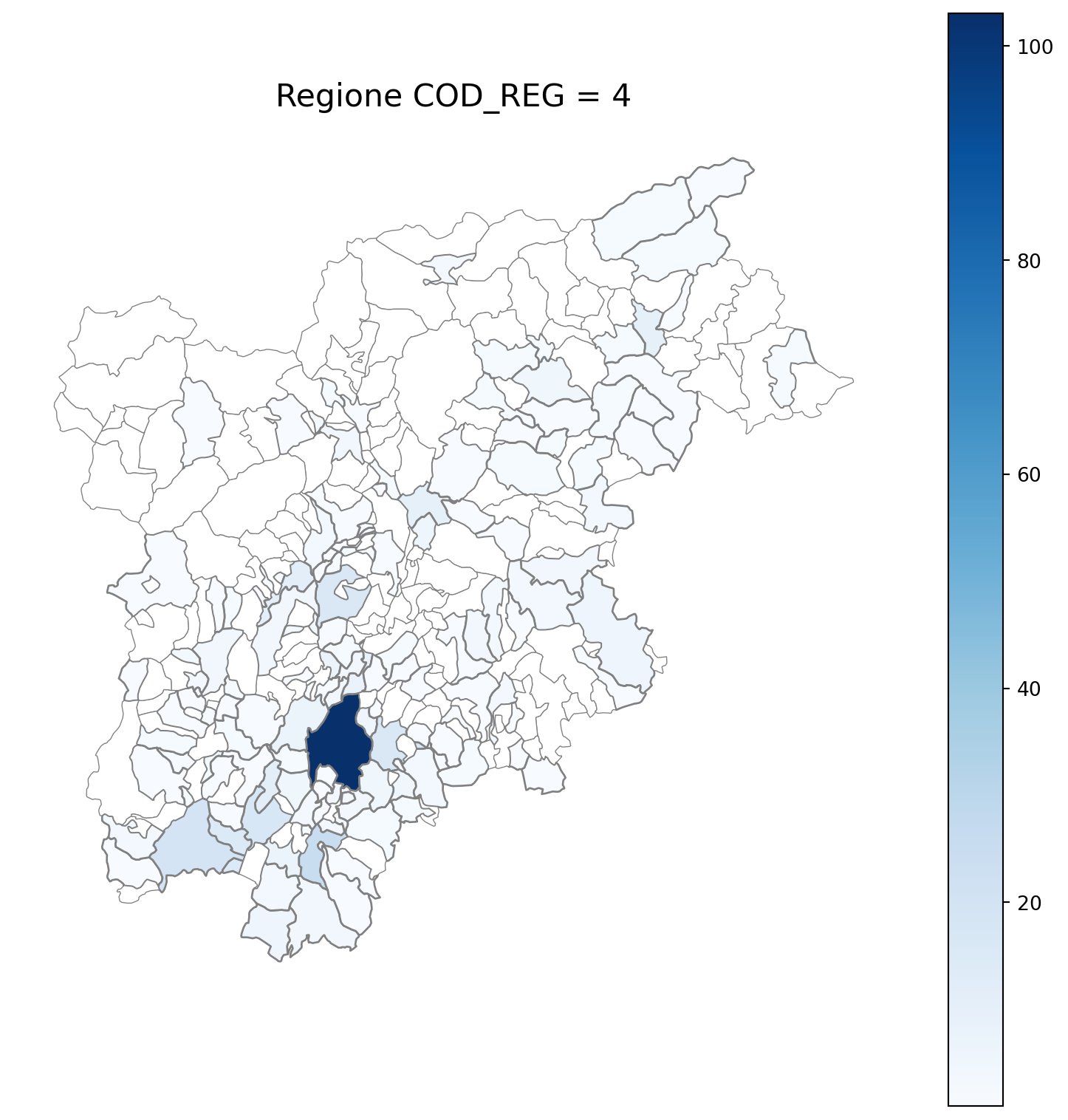
16 TRENTINO-ALTO ADIGE 535
19 VENETO 2338
5 FRIULI-VENEZIA GIULIA 696
7 LIGURIA 221
4 EMILIA-ROMAGNA 1777
15 TOSCANA 872
17 UMBRIA 230
9 MARCHE 493
6 LAZIO 1900
0 ABRUZZO 278
10 MOLISE 47
3 CAMPANIA 618
12 PUGLIA 595
1 BASILICATA 87
2 CALABRIA 203
14 SICILIA 581
13 SARDEGNA 274# Raggruppa i dati per COMUNE e conta le occorrenze
comuni_count = result2.groupby('COMUNE').size()
# Calcola le frequenze: quanti comuni hanno lo stesso numero di occorrenze
frequenza_comuni = comuni_count.value_counts().sort_index()
# Converte in DataFrame
frequenza_comuni_df = frequenza_comuni.reset_index()
frequenza_comuni_df.columns = ['Occorrenze', 'Numero di Comuni']
# Raggruppa per intervalli di occorrenze (opzionale, per esempio in gruppi di 10)
frequenza_comuni_df['Intervalli'] = pd.cut(frequenza_comuni_df['Occorrenze'], bins=range(0, frequenza_comuni_df['Occorrenze'].max() + 10, 10), right=False)
# Raggruppa per intervalli (se applicabile)
raggruppati = frequenza_comuni_df.groupby('Intervalli')['Numero di Comuni'].sum().reset_index()
# Mostra il risultato
raggruppatiC:\Users\paolo\AppData\Local\Temp\ipykernel_24916\338649489.py:15: FutureWarning:
The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
| Intervalli | Numero di Comuni | |
|---|---|---|
| 0 | [0, 10) | 3478 |
| 1 | [10, 20) | 232 |
| 2 | [20, 30) | 60 |
| 3 | [30, 40) | 16 |
| 4 | [40, 50) | 9 |
| ... | ... | ... |
| 103 | [1030, 1040) | 0 |
| 104 | [1040, 1050) | 0 |
| 105 | [1050, 1060) | 0 |
| 106 | [1060, 1070) | 0 |
| 107 | [1070, 1080) | 1 |
108 rows × 2 columns
import pandas as pd
# Raggruppa i dati per COMUNE e conta le occorrenze
comuni_count = result2.groupby('COMUNE').size()
# Calcola le frequenze: quanti comuni hanno lo stesso numero di occorrenze
frequenza_comuni = comuni_count.value_counts().sort_index()
# Converte in DataFrame
frequenza_comuni_df = frequenza_comuni.reset_index()
frequenza_comuni_df.columns = ['Occorrenze', 'Numero di Comuni']
# Raggruppa per intervalli di occorrenze
frequenza_comuni_df['Intervalli'] = pd.cut(frequenza_comuni_df['Occorrenze'],
bins=range(0, frequenza_comuni_df['Occorrenze'].max() + 10, 10),
right=False)
# raggruppati = frequenza_comuni_df.groupby('Intervalli')['Numero di Comuni'].sum().reset_index()
# raggruppati = raggruppati[raggruppati['Numero di Comuni'] > 0]raggruppati = frequenza_comuni_df.groupby('Intervalli', observed=True)['Numero di Comuni'].sum().reset_index()
print(raggruppati) Intervalli Numero di Comuni
0 [0, 10) 3478
1 [10, 20) 232
2 [20, 30) 60
3 [30, 40) 16
4 [40, 50) 9
5 [50, 60) 6
6 [60, 70) 2
7 [70, 80) 3
8 [80, 90) 1
9 [90, 100) 1
10 [100, 110) 4
11 [110, 120) 2
12 [120, 130) 1
13 [650, 660) 1
14 [1070, 1080) 1import matplotlib.pyplot as plt
# Crea il grafico a barre
plt.figure(figsize=(10, 6))
plt.bar(raggruppati['Intervalli'].astype(str), raggruppati['Numero di Comuni'])
# Personalizza il grafico
plt.title('Distribuzione dei Comuni per Intervalli di Occorrenze', fontsize=16)
plt.xlabel('Intervalli di Occorrenze', fontsize=12)
plt.ylabel('Numero di Comuni', fontsize=12)
plt.xticks(rotation=45, ha='right') # Ruota le etichette sull'asse x per leggibilità
plt.grid(axis='y', linestyle='--', alpha=0.7)
# Mostra il grafico
plt.tight_layout()
plt.show()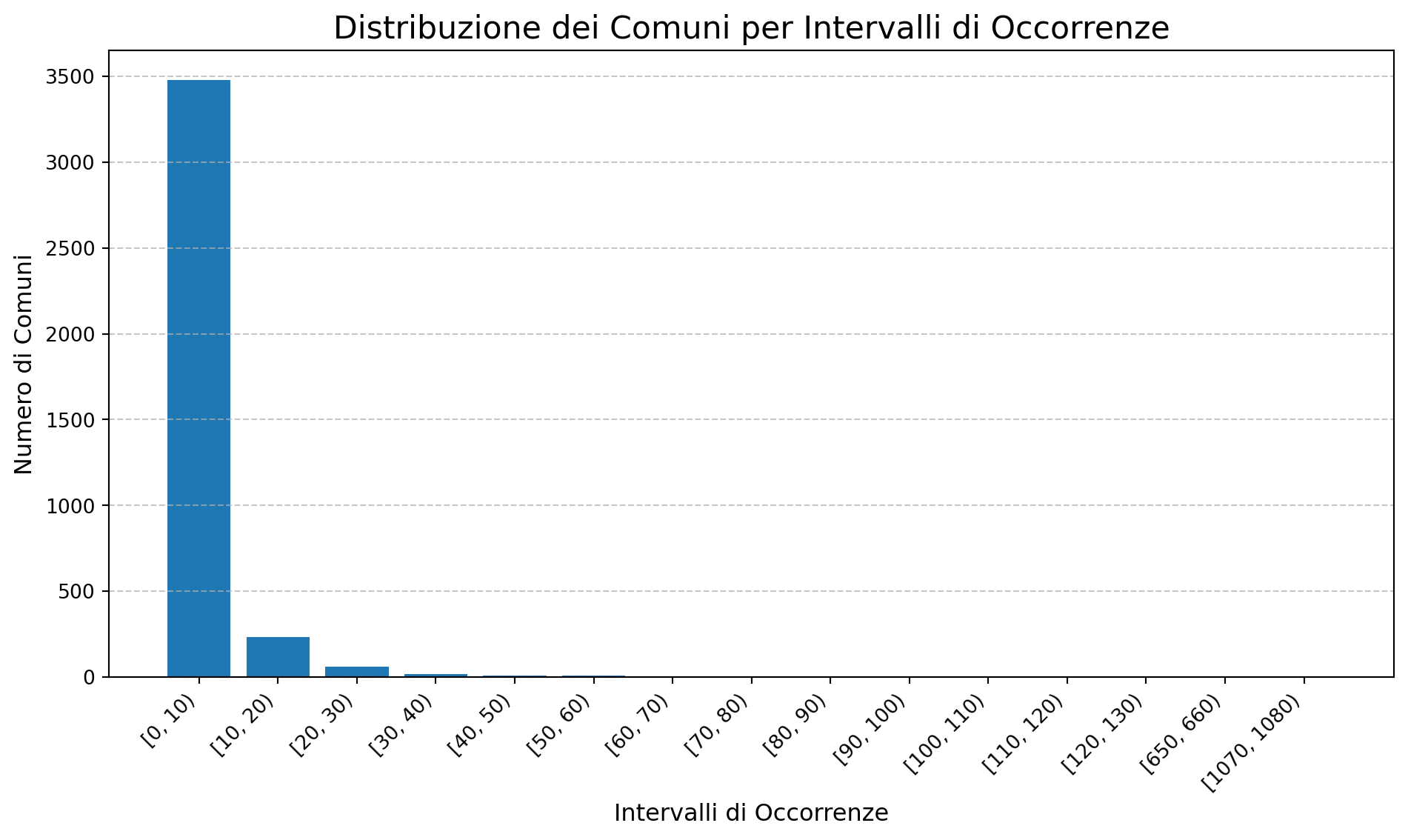
# Raggruppa i dati per COMUNE e conta le occorrenze
comuni_count = result2.groupby('COMUNE').size()
# Filtra i comuni con un numero di occorrenze inferiore o uguale a 10
comuni_max_10 = comuni_count[comuni_count >= 400].index.unique()
# Mostra i comuni unici
print(comuni_max_10)Index(['MILANO', 'ROMA'], dtype='object', name='COMUNE')# Calcola il numero di occorrenze per ogni comune
comuni_count = result2.groupby('COMUNE').size().reset_index()
comuni_count.columns = ['COMUNE', 'Occorrenze']
# Aggiungi una colonna per gli intervalli
comuni_count['Intervalli'] = pd.cut(comuni_count['Occorrenze'],
bins=range(0, comuni_count['Occorrenze'].max() + 10, 10),
right=False)
# Raggruppa i comuni per intervalli
comuni_per_intervallo = comuni_count.groupby('Intervalli')['COMUNE'].unique().reset_index()
# Mostra il risultato
print(comuni_per_intervallo) Intervalli COMUNE
0 [0, 10) [ABBADIA LARIANA, ACATE, ACERRA, ACI BONACCORS...
1 [10, 20) [ABANO TERME, ABBIATEGRASSO, AGRIGENTO, ALBA, ...
2 [20, 30) [AGEROLA, ALBIGNASEGO, ALESSANDRIA, ANZIO, ARE...
3 [30, 40) [ANCONA, CARPI, FIUMICINO, GUIDONIA MONTECELIO...
4 [40, 50) [BARI, BUSTO ARSIZIO, CAGLIARI, CESENA, FORLI'...
.. ... ...
103 [1030, 1040) []
104 [1040, 1050) []
105 [1050, 1060) []
106 [1060, 1070) []
107 [1070, 1080) [ROMA]
[108 rows x 2 columns]C:\Users\paolo\AppData\Local\Temp\ipykernel_24916\1272126017.py:11: FutureWarning:
The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
# Calcola il numero di occorrenze per ogni comune
comuni_count = result2.groupby('COMUNE').size().reset_index()
comuni_count.columns = ['COMUNE', 'Occorrenze']
# Aggiungi una colonna per gli intervalli
comuni_count['Intervalli'] = pd.cut(comuni_count['Occorrenze'],
bins=range(0, comuni_count['Occorrenze'].max() + 10, 10),
right=False)
# Raggruppa i comuni per intervalli, escludendo i raggruppamenti con valore 0
comuni_per_intervallo = comuni_count.groupby('Intervalli').filter(lambda x: x['Occorrenze'].sum() > 0)
# Raggruppa nuovamente per intervalli e ottieni i comuni unici
comuni_per_intervallo = comuni_per_intervallo.groupby('Intervalli')['COMUNE'].unique().reset_index()
# Mostra il risultato
(comuni_per_intervallo)C:\Users\paolo\AppData\Local\Temp\ipykernel_24916\1766664538.py:11: FutureWarning:
The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
C:\Users\paolo\AppData\Local\Temp\ipykernel_24916\1766664538.py:14: FutureWarning:
The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
| Intervalli | COMUNE | |
|---|---|---|
| 0 | [0, 10) | [ABBADIA LARIANA, ACATE, ACERRA, ACI BONACCORS... |
| 1 | [10, 20) | [ABANO TERME, ABBIATEGRASSO, AGRIGENTO, ALBA, ... |
| 2 | [20, 30) | [AGEROLA, ALBIGNASEGO, ALESSANDRIA, ANZIO, ARE... |
| 3 | [30, 40) | [ANCONA, CARPI, FIUMICINO, GUIDONIA MONTECELIO... |
| 4 | [40, 50) | [BARI, BUSTO ARSIZIO, CAGLIARI, CESENA, FORLI'... |
| ... | ... | ... |
| 103 | [1030, 1040) | [] |
| 104 | [1040, 1050) | [] |
| 105 | [1050, 1060) | [] |
| 106 | [1060, 1070) | [] |
| 107 | [1070, 1080) | [ROMA] |
108 rows × 2 columns
# Importa le librerie necessarie
import pandas as pd
# Calcola il numero di occorrenze per ogni comune
comuni_count = result2.groupby('COMUNE').size().reset_index()
comuni_count.columns = ['COMUNE', 'Occorrenze']
# Aggiungi una colonna per gli intervalli
comuni_count['Intervalli'] = pd.cut(comuni_count['Occorrenze'],
bins=range(0, comuni_count['Occorrenze'].max() + 10, 10),
right=False)
# Raggruppa per intervalli e ottieni i comuni unici
comuni_per_intervallo = comuni_count.groupby('Intervalli', observed=False)['COMUNE'].unique().reset_index()
# Filtra per rimuovere intervalli con liste vuote
comuni_per_intervallo = comuni_per_intervallo[comuni_per_intervallo['COMUNE'].str.len() > 0]
# Mostra il risultato
(comuni_per_intervallo)| Intervalli | COMUNE | |
|---|---|---|
| 0 | [0, 10) | [ABBADIA LARIANA, ACATE, ACERRA, ACI BONACCORS... |
| 1 | [10, 20) | [ABANO TERME, ABBIATEGRASSO, AGRIGENTO, ALBA, ... |
| 2 | [20, 30) | [AGEROLA, ALBIGNASEGO, ALESSANDRIA, ANZIO, ARE... |
| 3 | [30, 40) | [ANCONA, CARPI, FIUMICINO, GUIDONIA MONTECELIO... |
| 4 | [40, 50) | [BARI, BUSTO ARSIZIO, CAGLIARI, CESENA, FORLI'... |
| 5 | [50, 60) | [COMO, FERRARA, LATINA, PERUGIA, RAVENNA, VICE... |
| 6 | [60, 70) | [FIRENZE, UDINE] |
| 7 | [70, 80) | [BERGAMO, MONZA, VENEZIA] |
| 8 | [80, 90) | [REGGIO NELL'EMILIA] |
| 9 | [90, 100) | [BOLOGNA] |
| 10 | [100, 110) | [BRESCIA, PARMA, TRENTO, VERONA] |
| 11 | [110, 120) | [MODENA, TORINO] |
| 12 | [120, 130) | [PADOVA] |
| 65 | [650, 660) | [MILANO] |
| 107 | [1070, 1080) | [ROMA] |
2.5 mappa Italia
import geopandas as gpdcomuni = result2.groupby('COMUNE')['COMUNE'].count().reset_index(name='count')
df1 = gpd.read_file('D:/files/csv/Shapefile/Limiti01012023_g/Com01012023_g/Com01012023_g_WGS84.shp')
df1['COMUNE'] = df1['COMUNE'].str.upper()
merged_gdf = df1.merge(comuni, left_on='COMUNE', right_on='COMUNE', how='inner')
# merged_gdf.to_csv('D:\\files\\csv\\Colonnine_elettriche\\merged.csv', sep='|', index = False)ax = merged_gdf.plot(
column='count', # Usa la colonna 'count' per definire i colori
cmap='tab10', # Scegli una mappa di colori
figsize=(12, 12), # Imposta la dimensione
legend=False # Mostra la legenda
)
ax.axis('off')
plt.savefig(f"D:/Italia.png", dpi=300, bbox_inches='tight', pad_inches=0.1)
plt.show()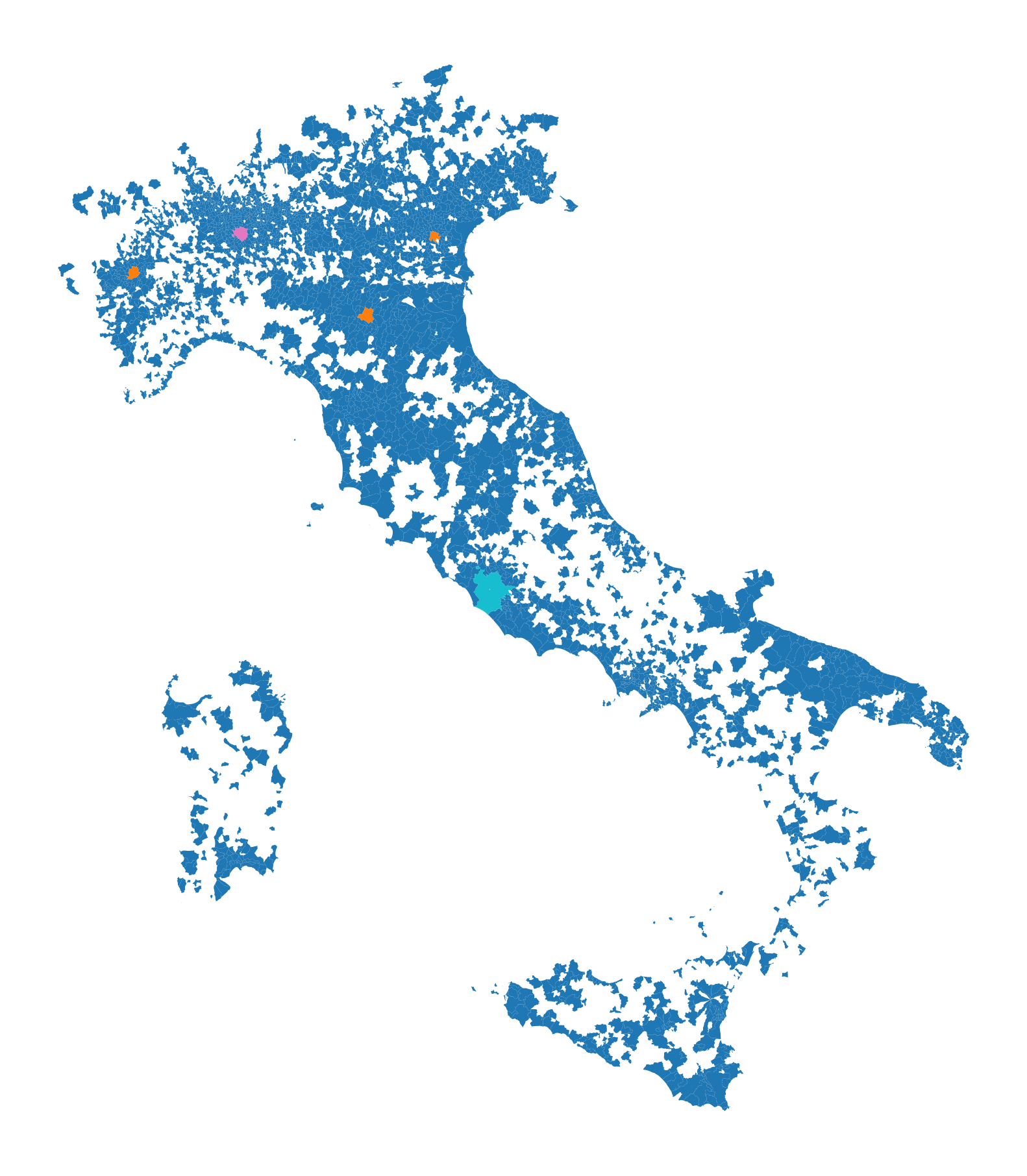
comuni = result2.groupby('COMUNE')['COMUNE'].count().reset_index(name='count')
df1 = gpd.read_file('D:/files/csv/Shapefile/Limiti01012023_g/Com01012023_g/Com01012023_g_WGS84.shp')
df1['COMUNE'] = df1['COMUNE'].str.upper()
merged_gdf = df1.merge(comuni, left_on='COMUNE', right_on='COMUNE', how='left')2.6 singole regioni
for i in range(1, 21):
# Filtra temporaneamente il DataFrame per ogni valore di COD_REG
temp_gdf = merged_gdf.query('COD_REG == @i')
# Crea una nuova figura per ogni grafico
fig, ax = plt.subplots(figsize=(10, 10))
# Traccia il confine (opzionale, usa temp_gdf o merged_gdf per i bordi)
temp_gdf.plot(ax=ax, color='black', linewidth=5)
# Traccia la mappa colorata in base alla colonna 'count'
temp_gdf.plot(column='count', cmap='Reds', ax=ax, legend=False, missing_kwds={
"color": "white", # Colore per i NaN
"edgecolor": "black", # Contorno nero
"linewidth": 1
})
# Aggiungi titolo e dettagli
ax.set_title(f"Regione COD_REG = {i}", fontsize=16)
ax.axis('off') # Mantieni gli assi visibili (è già il comportamento predefinito)
# Mostra la figura
plt.show()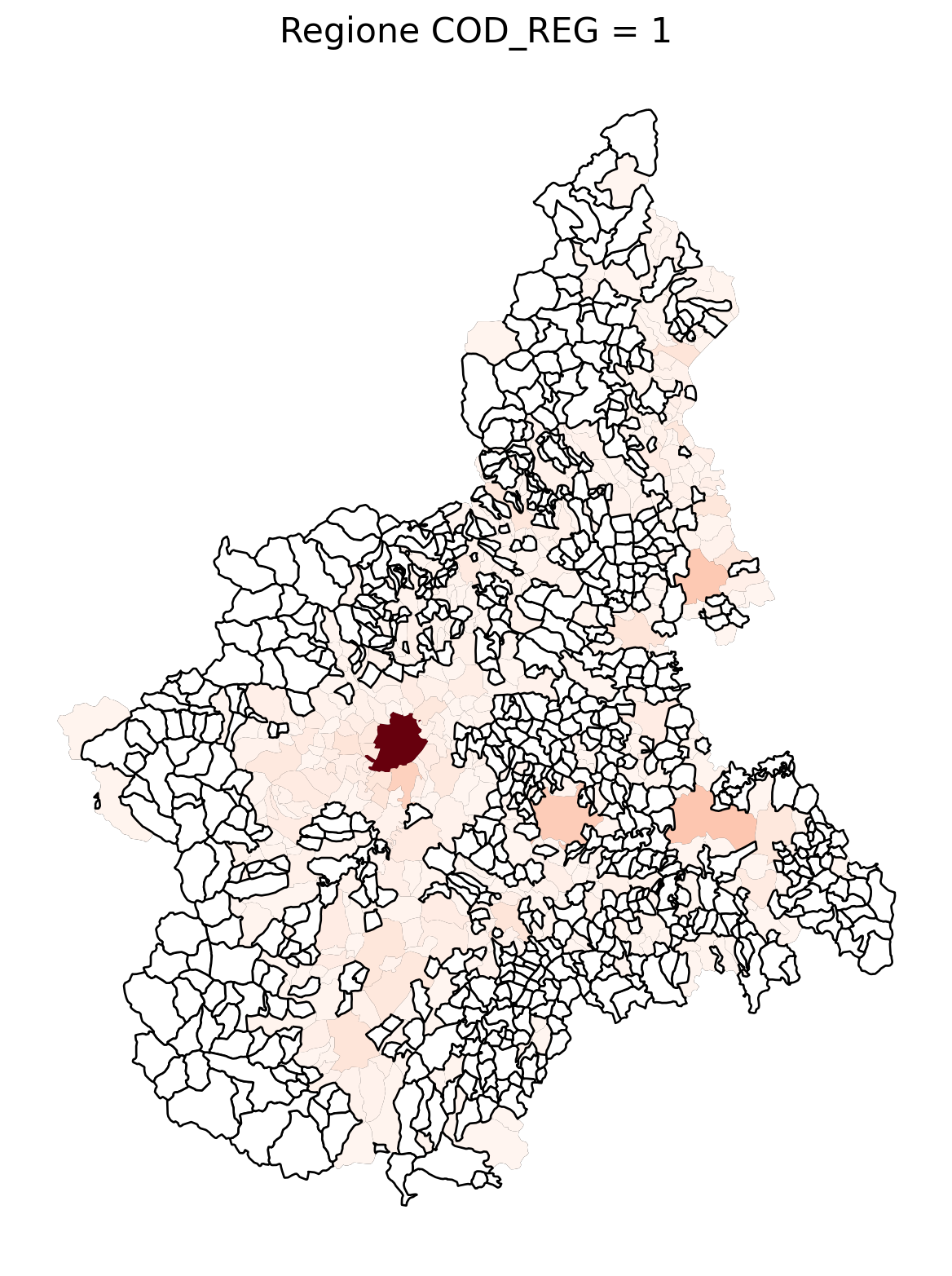
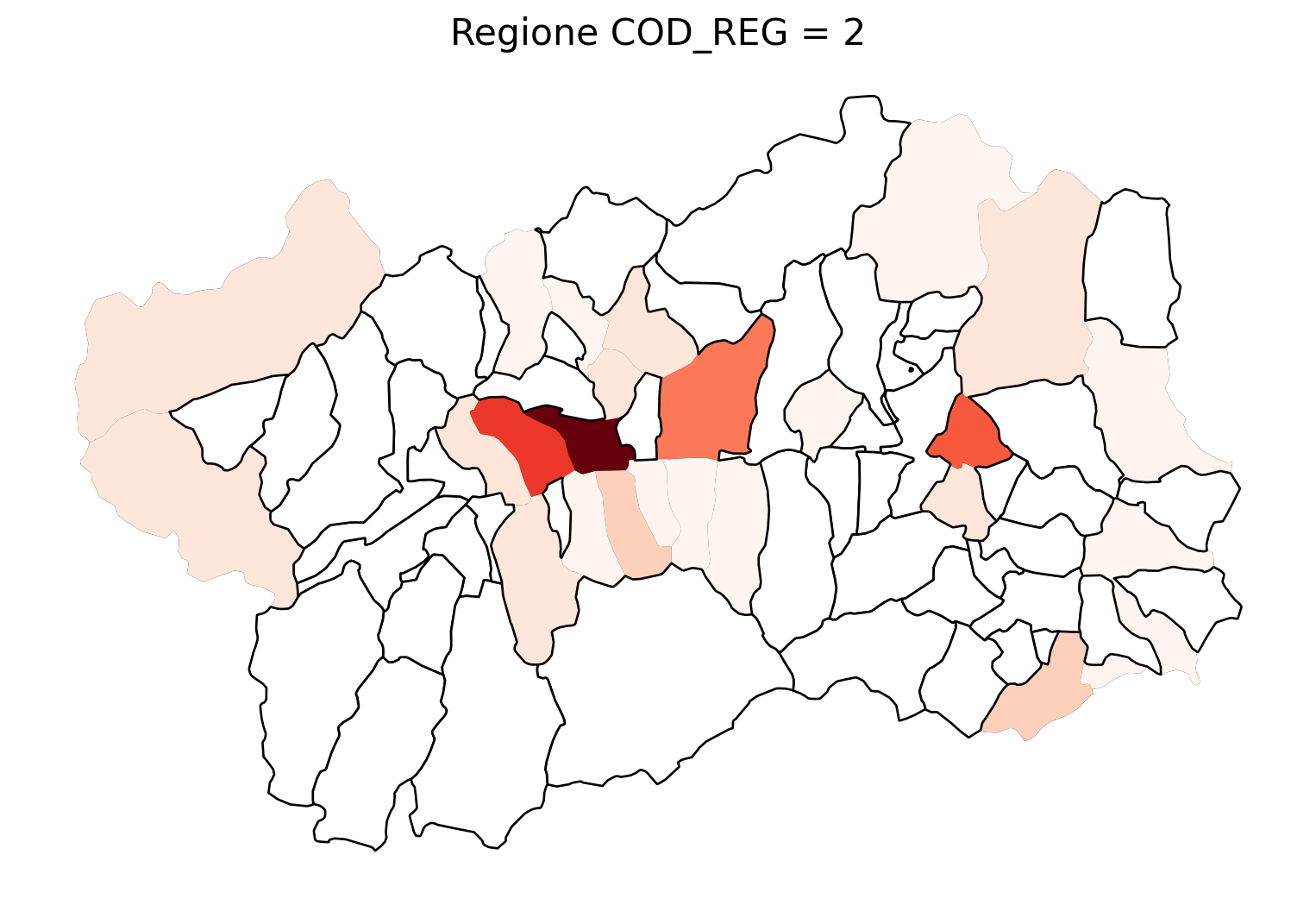
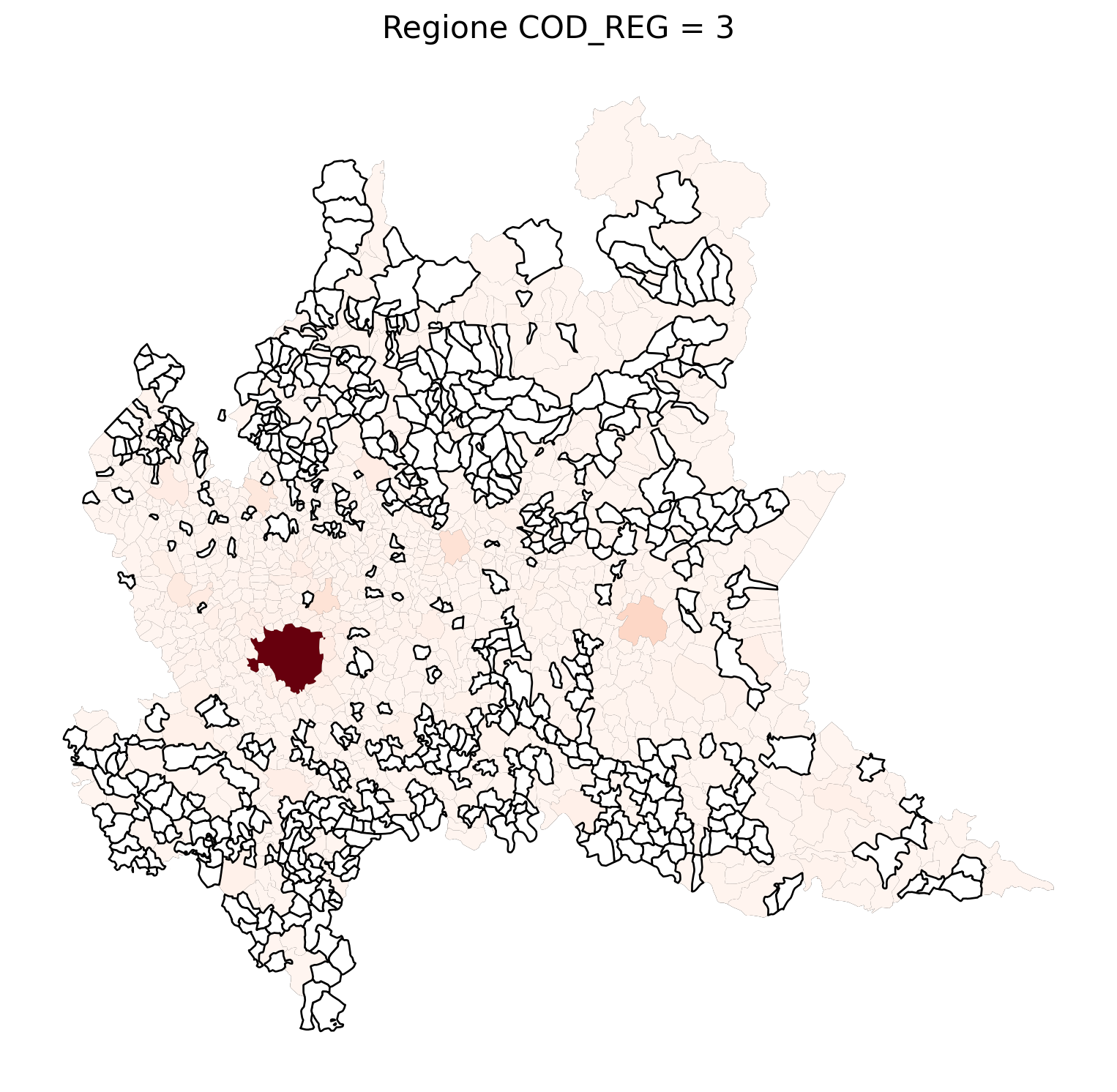
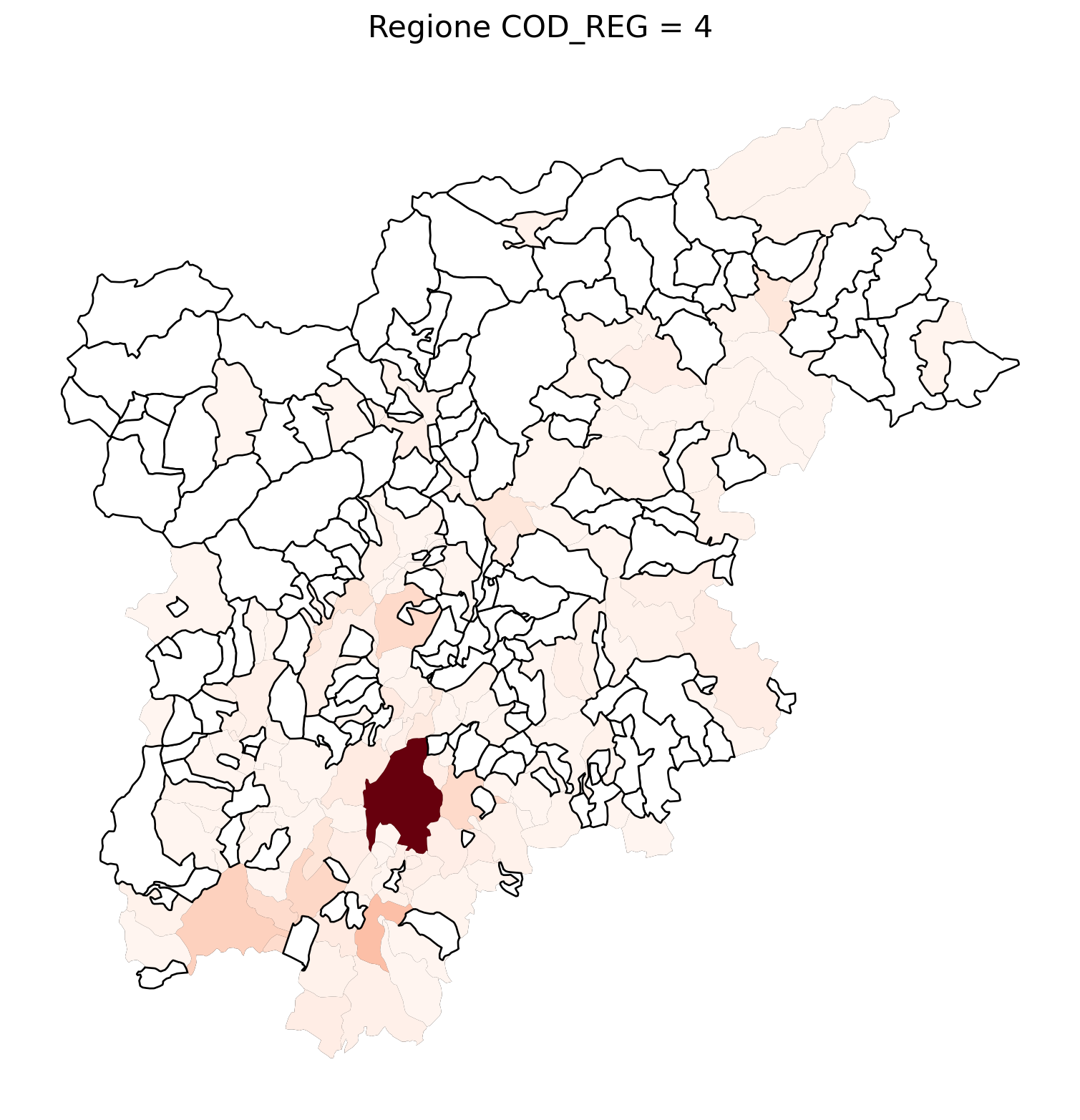
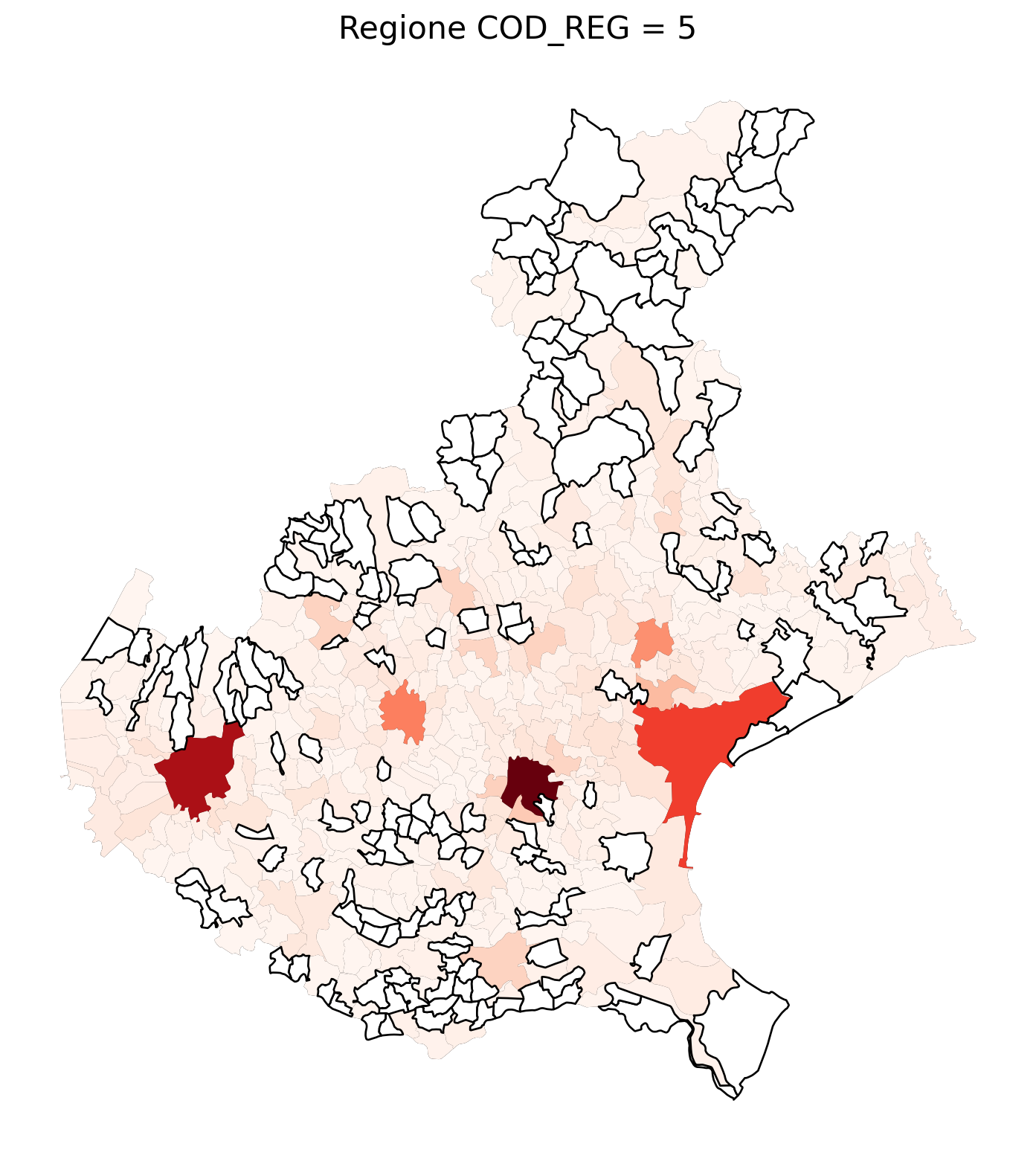
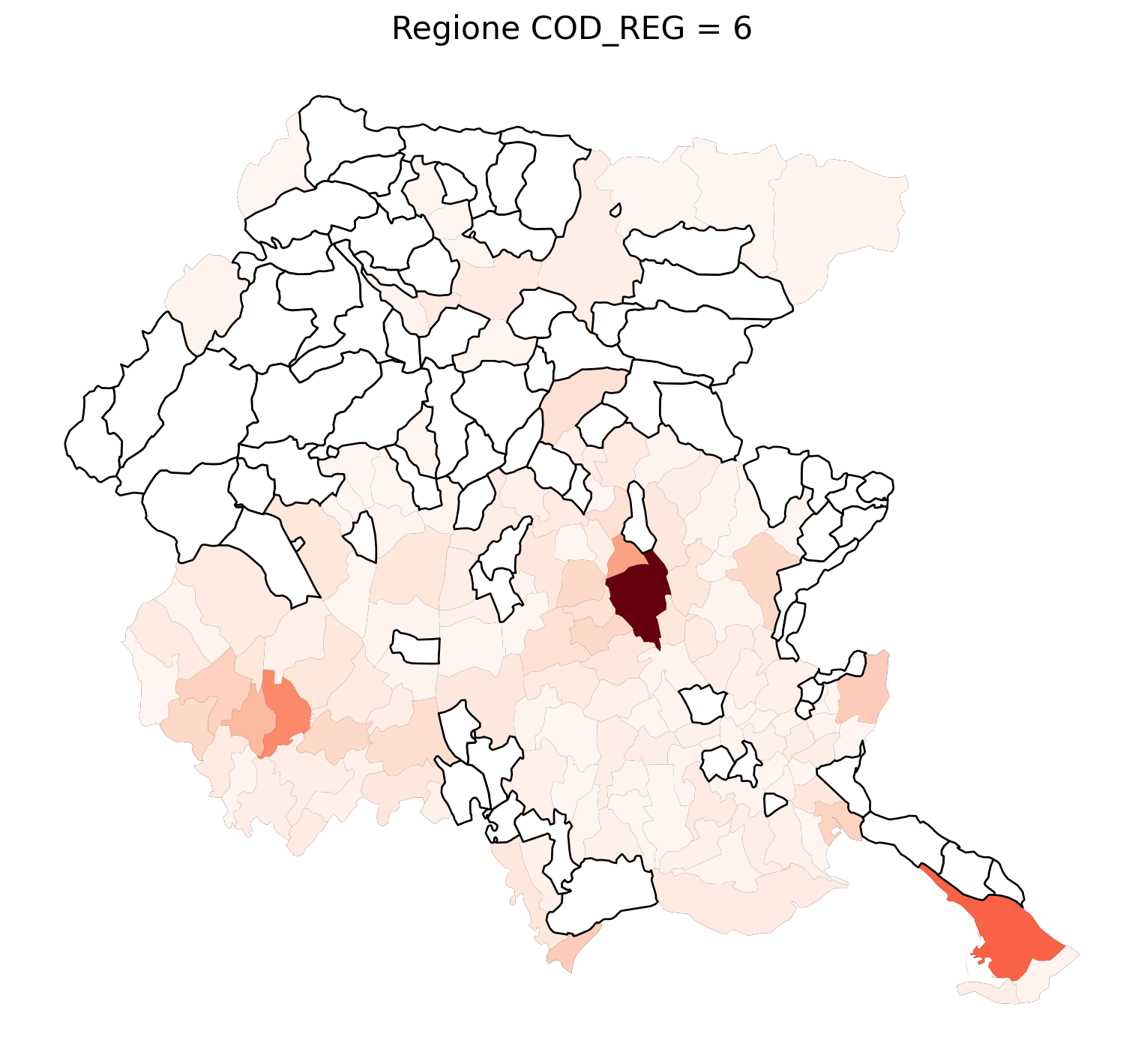
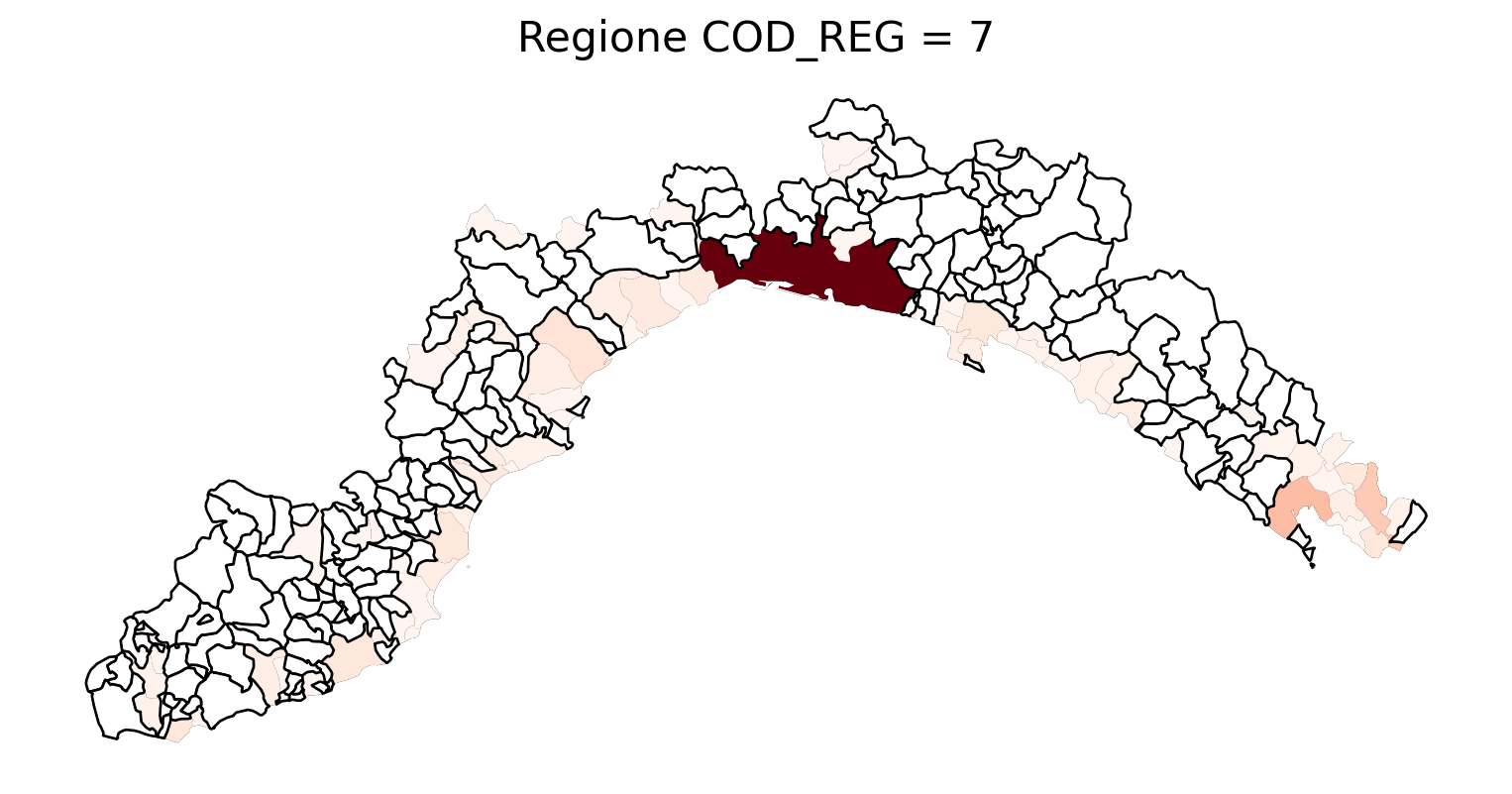
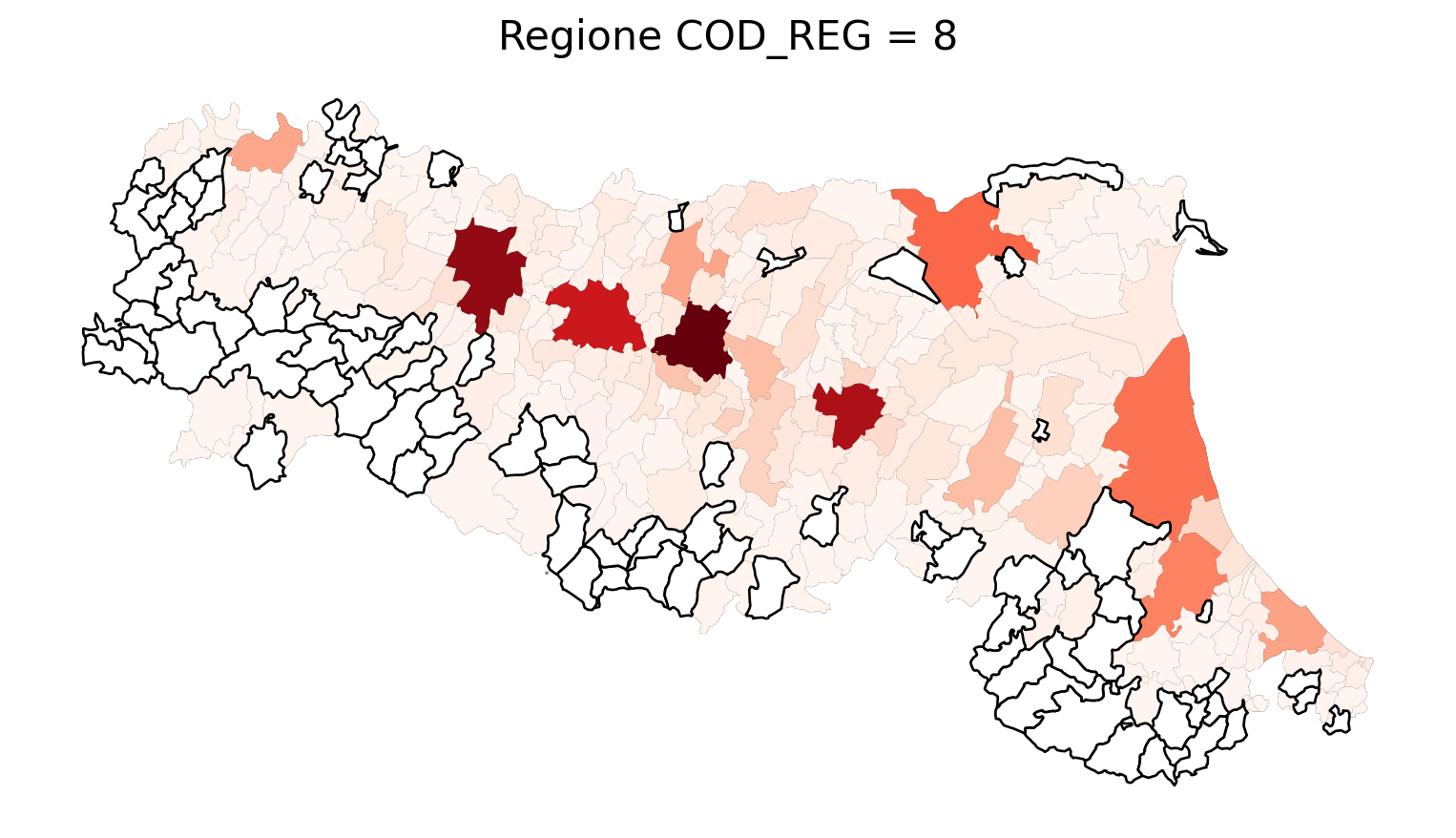
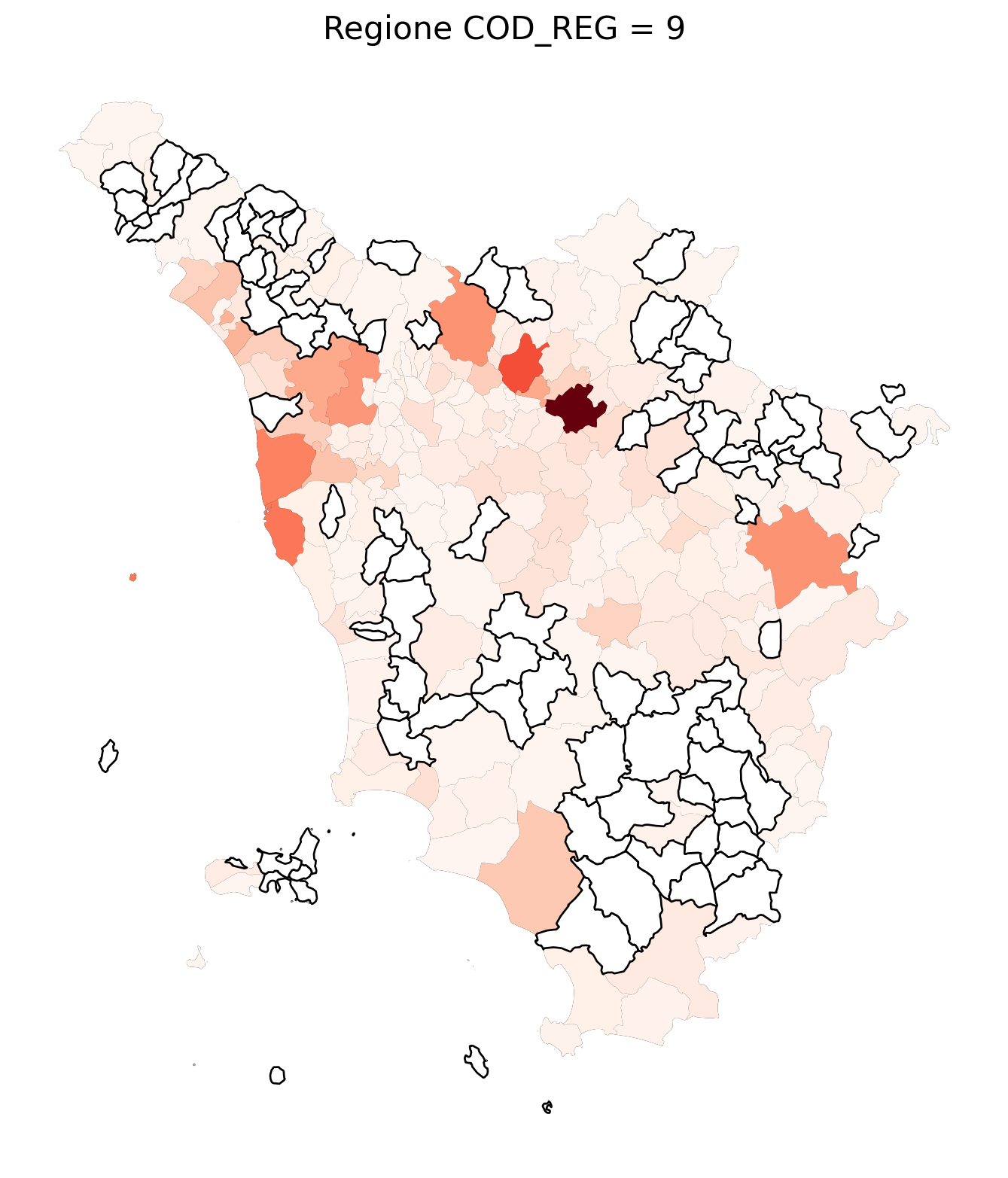
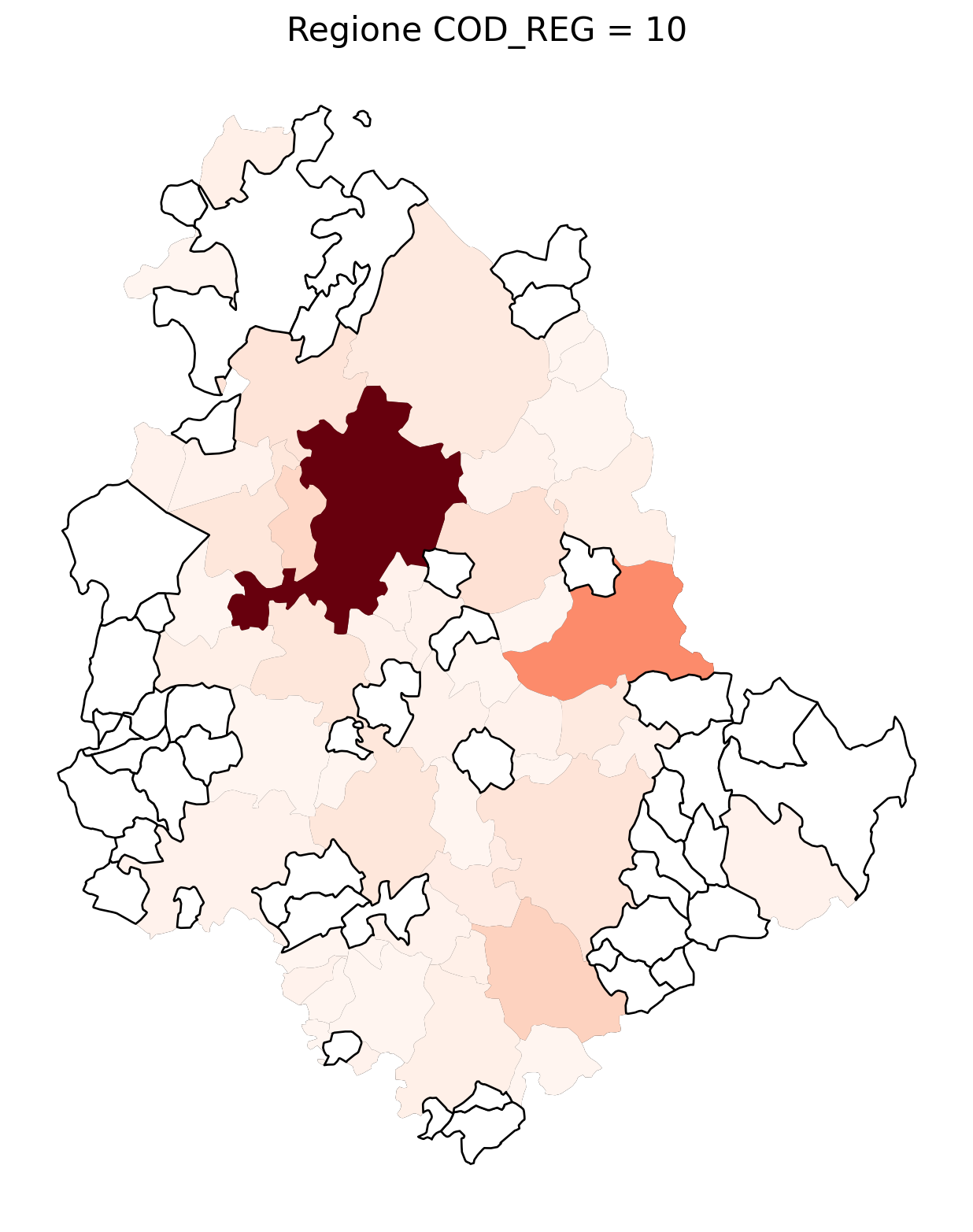
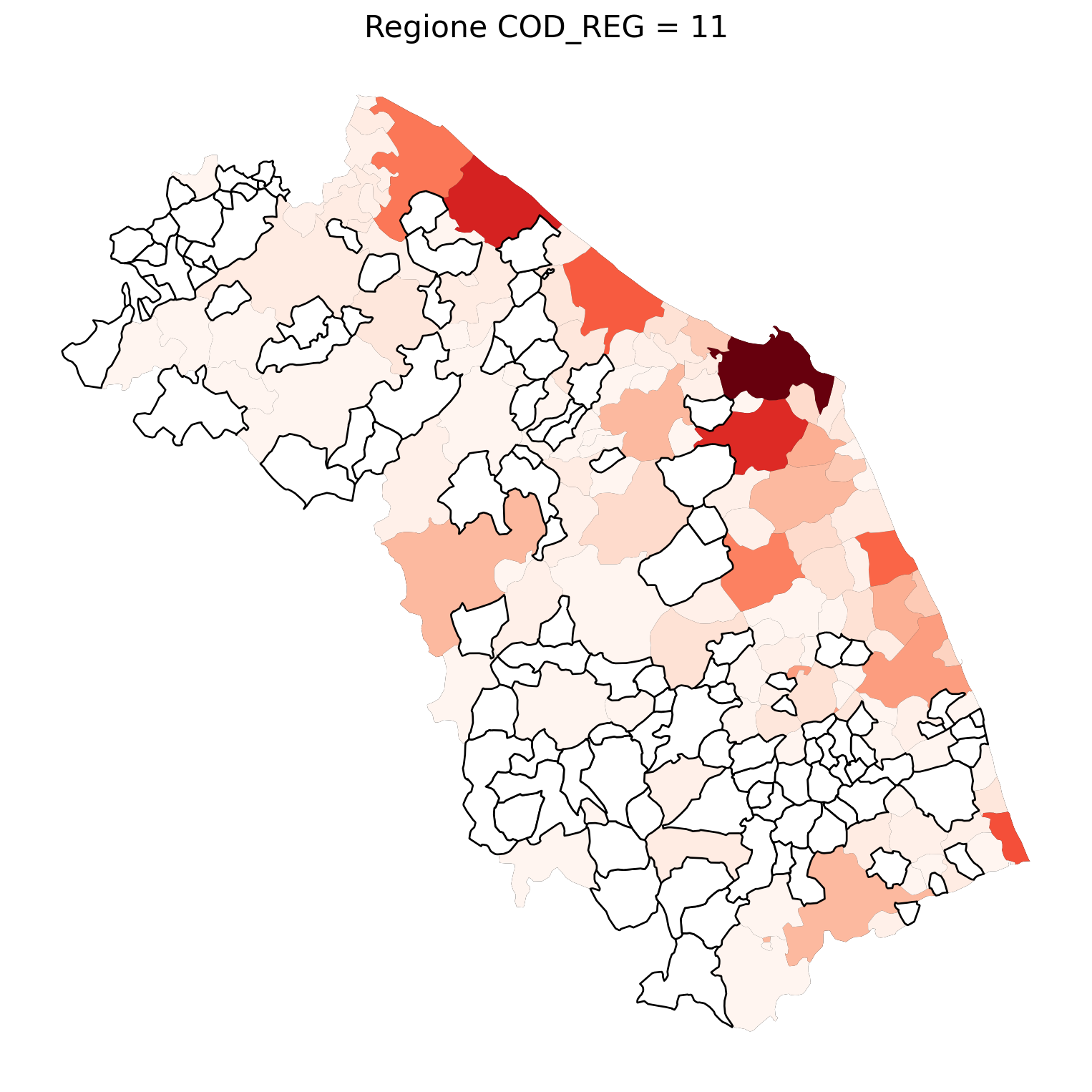
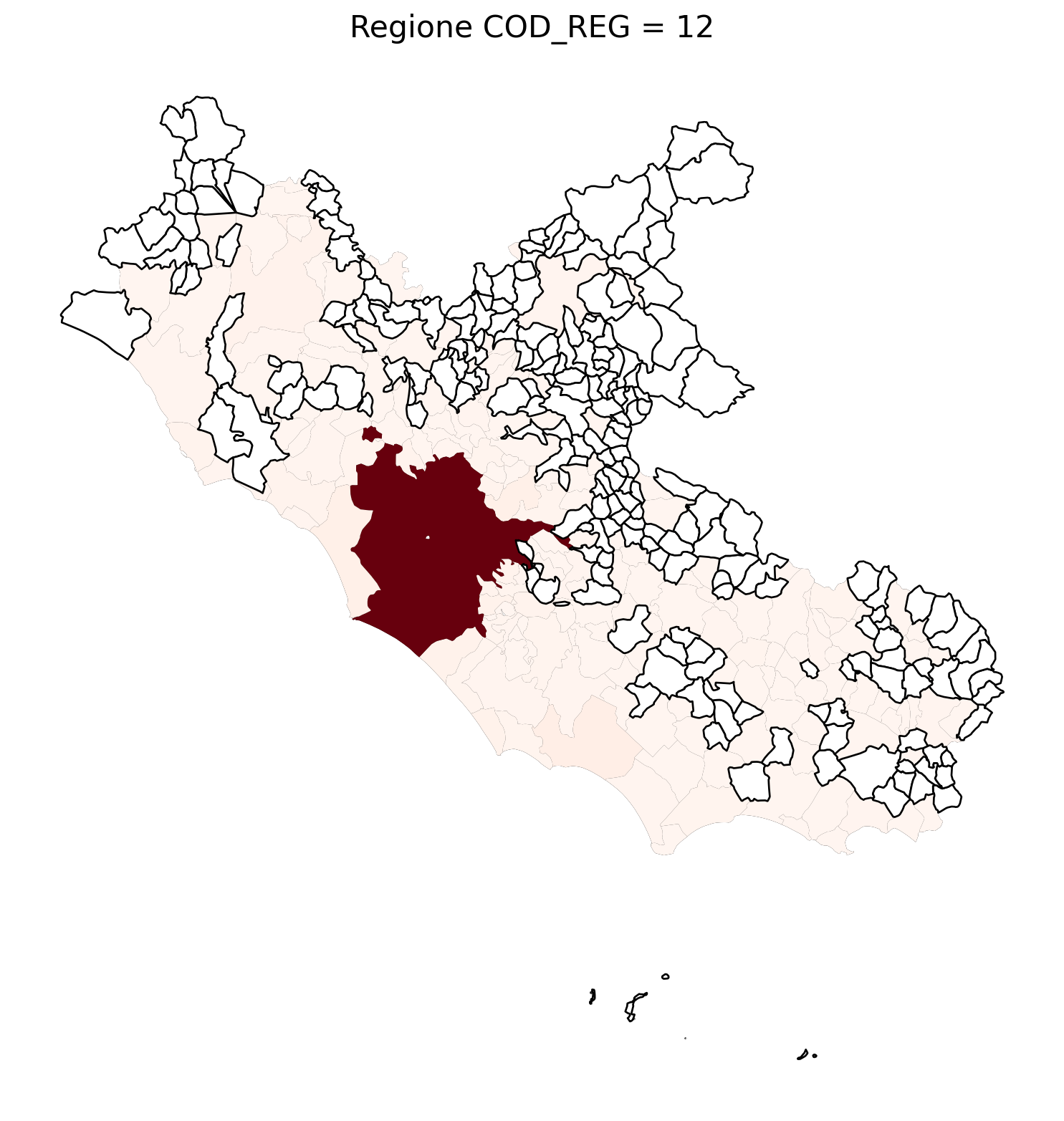
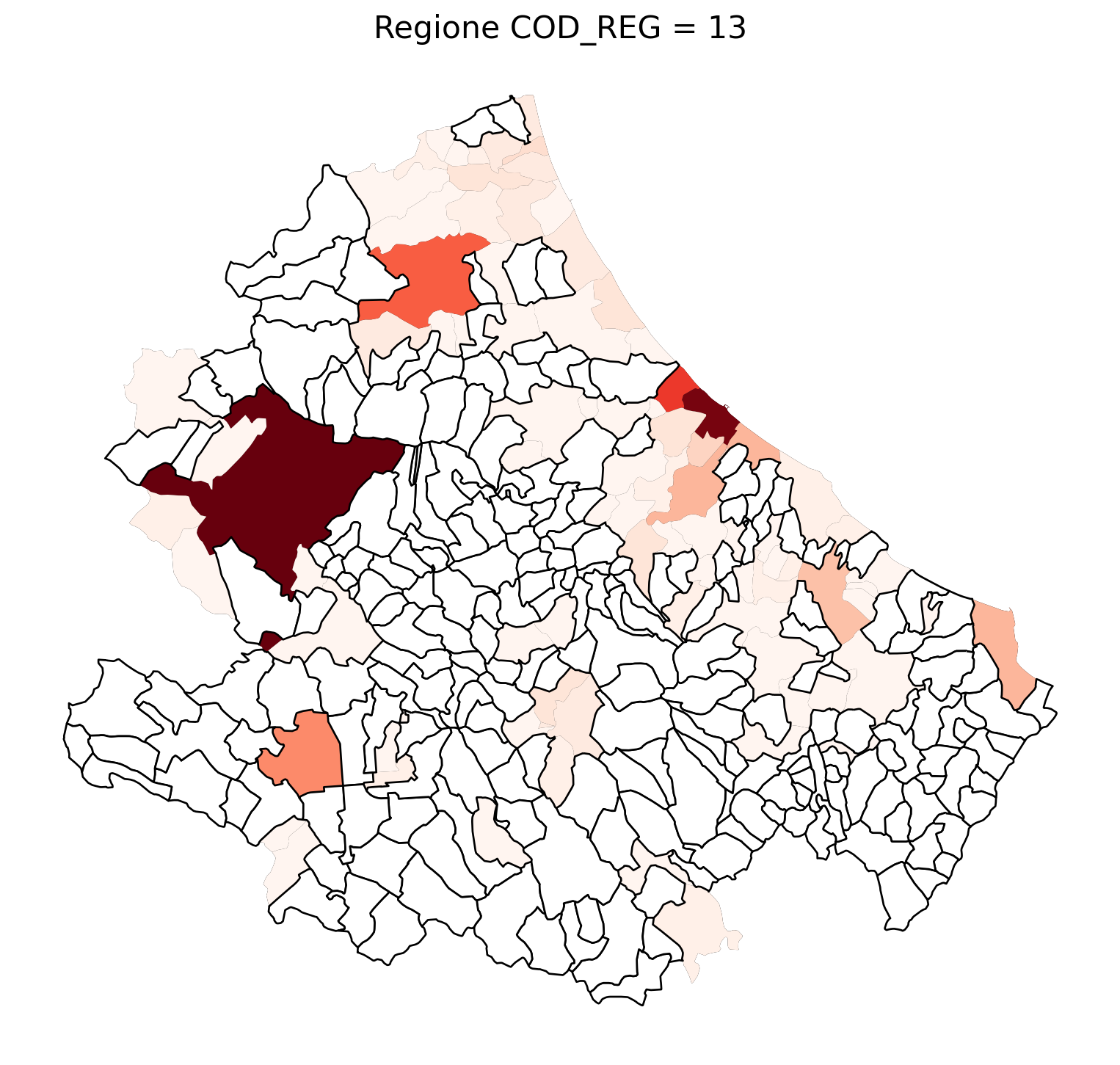
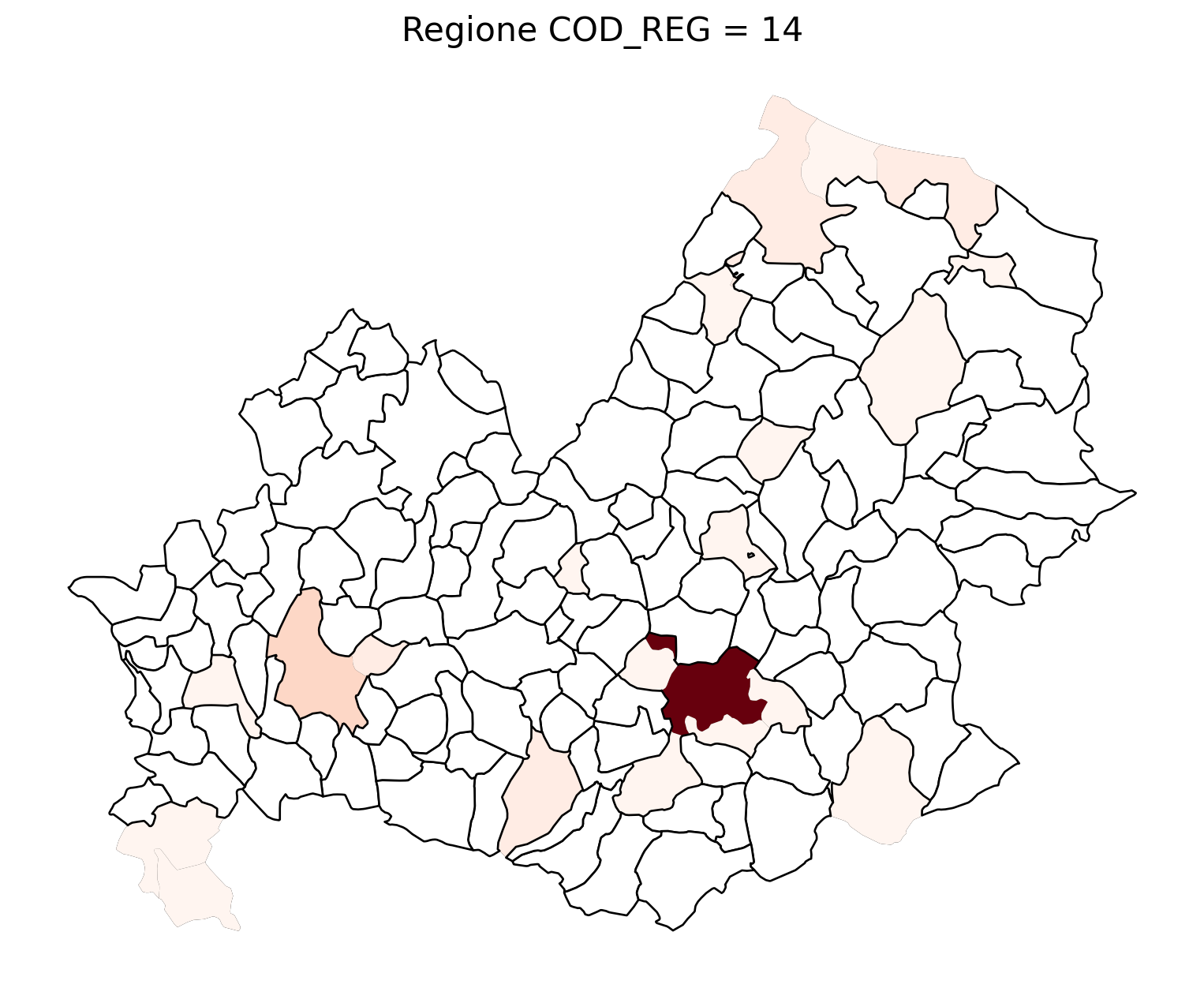
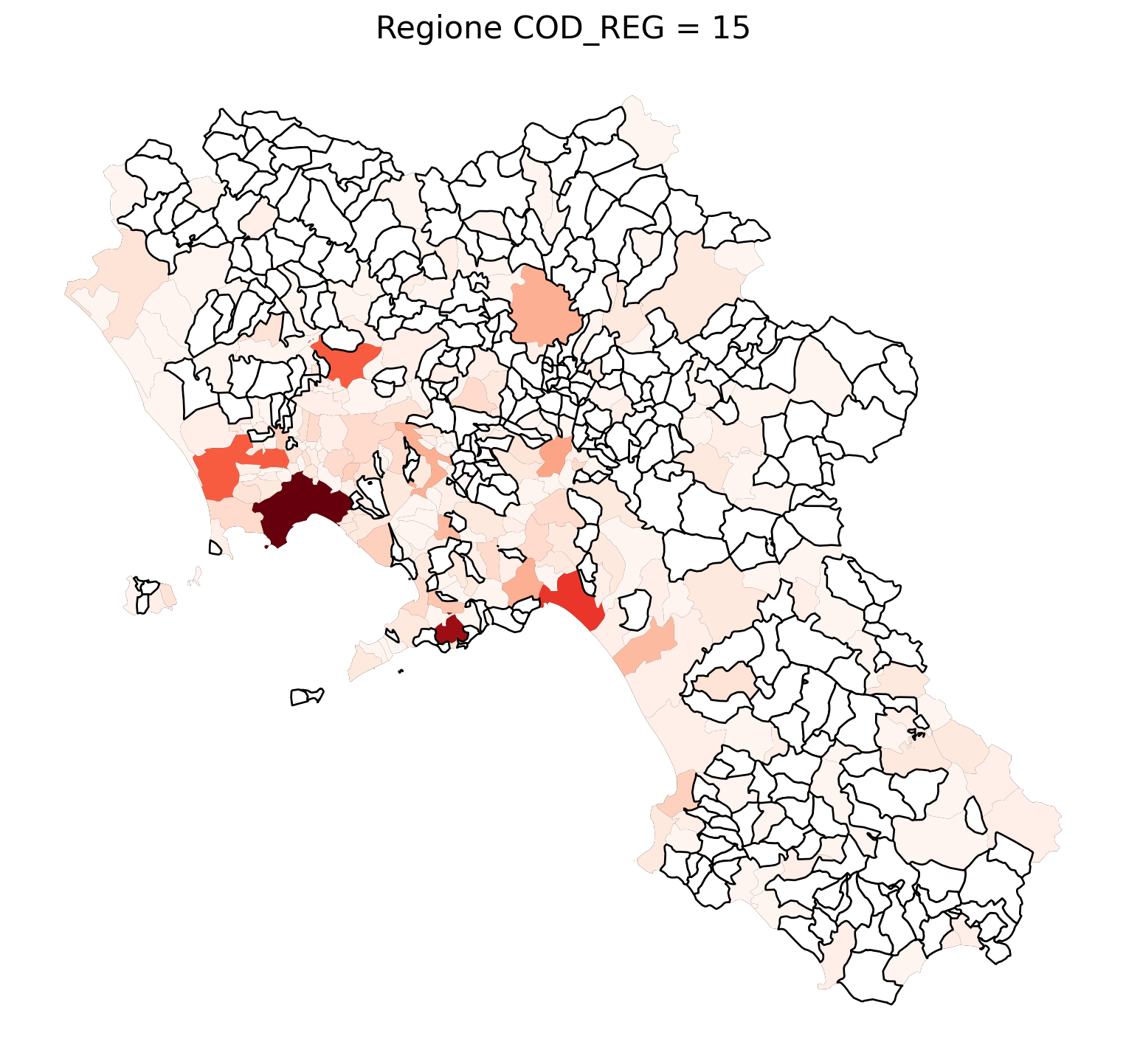
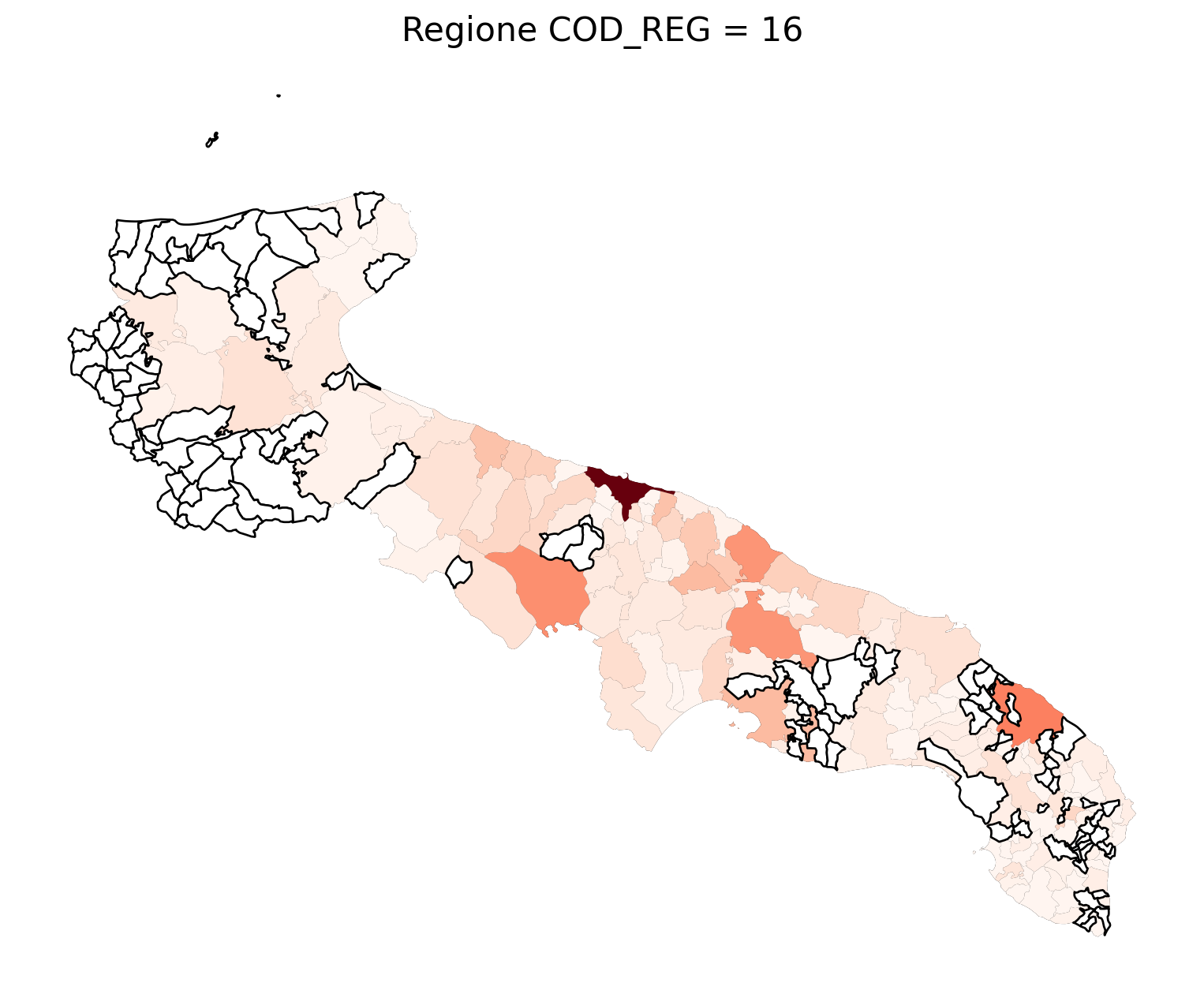
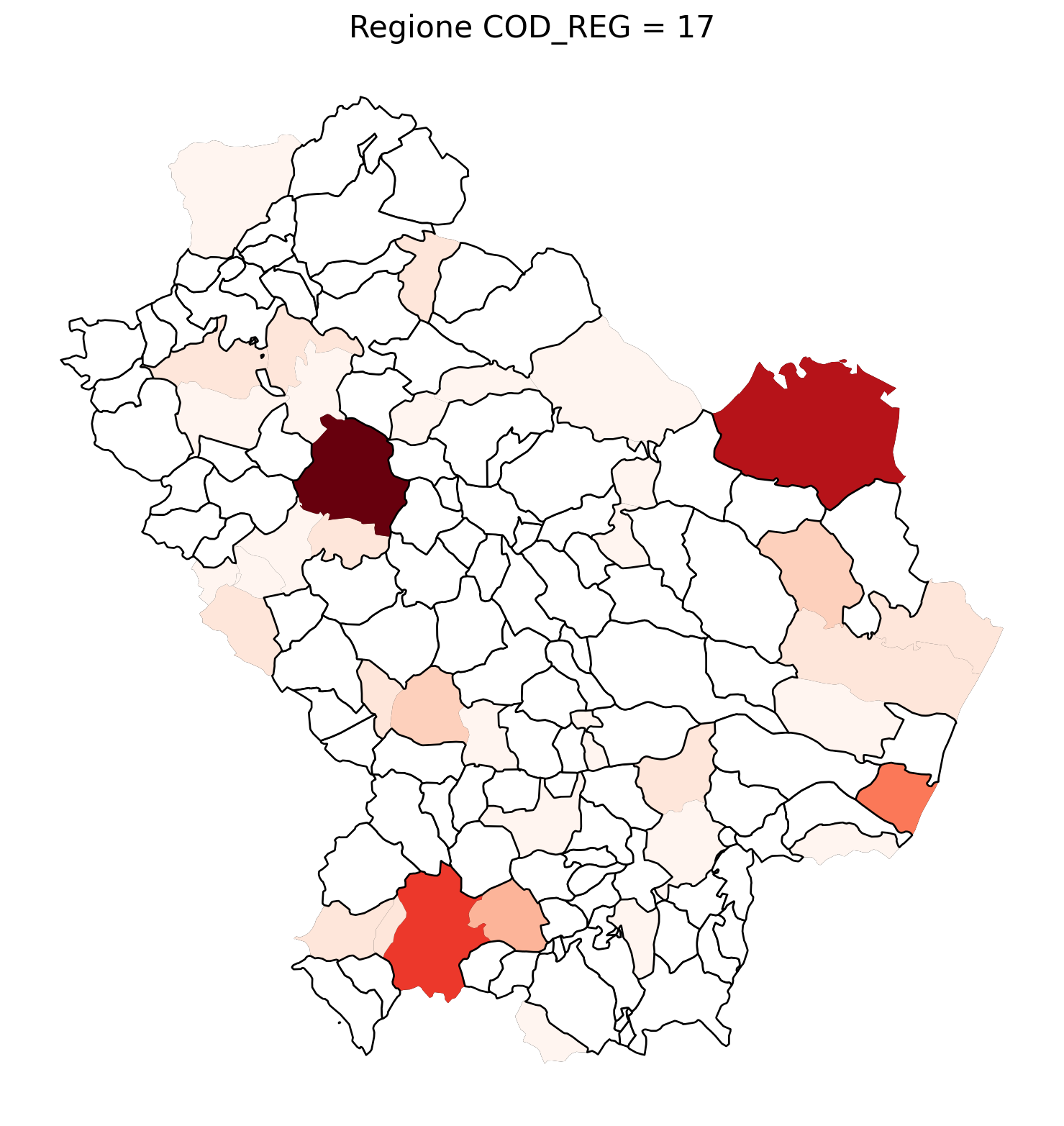
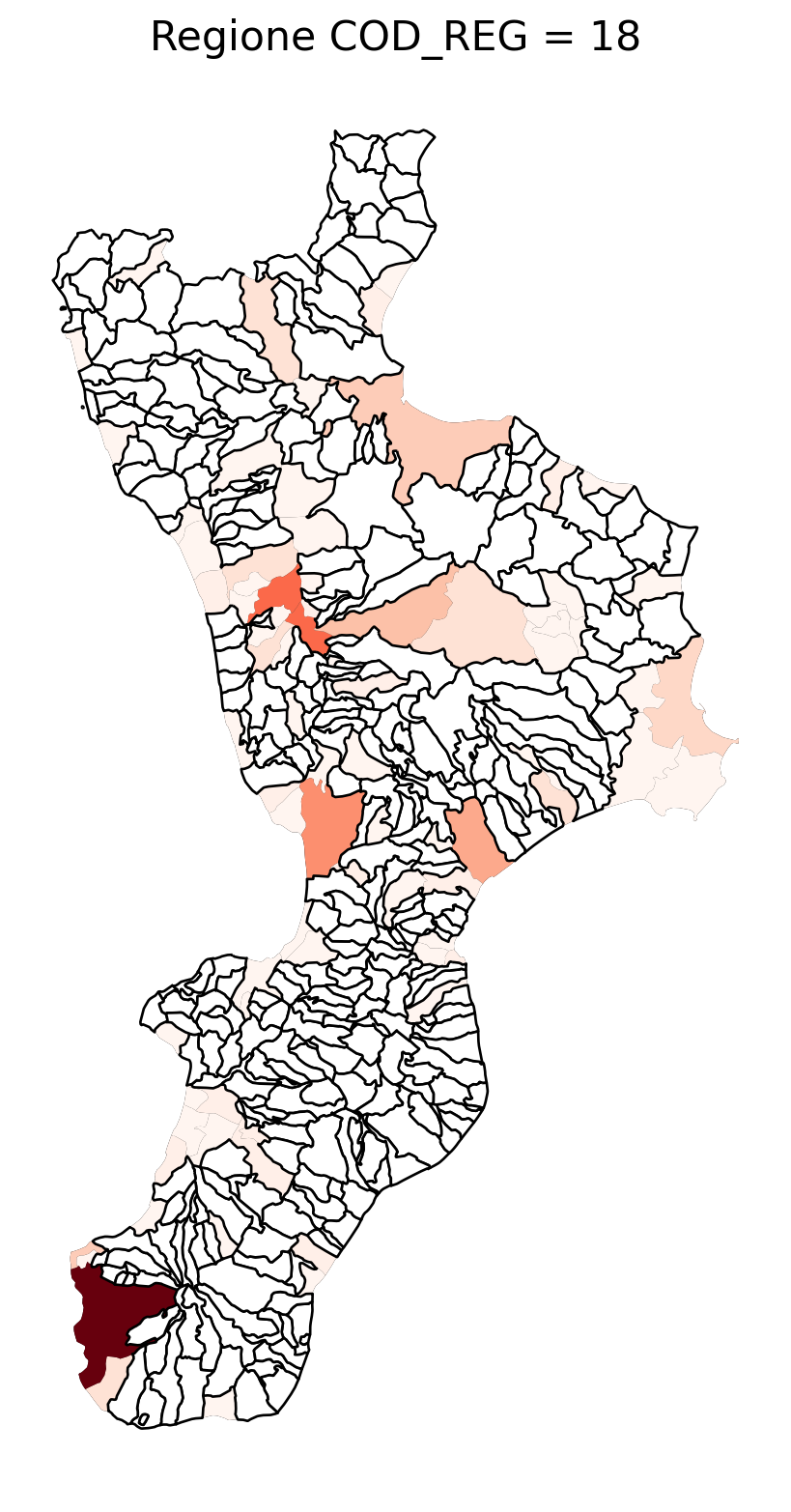
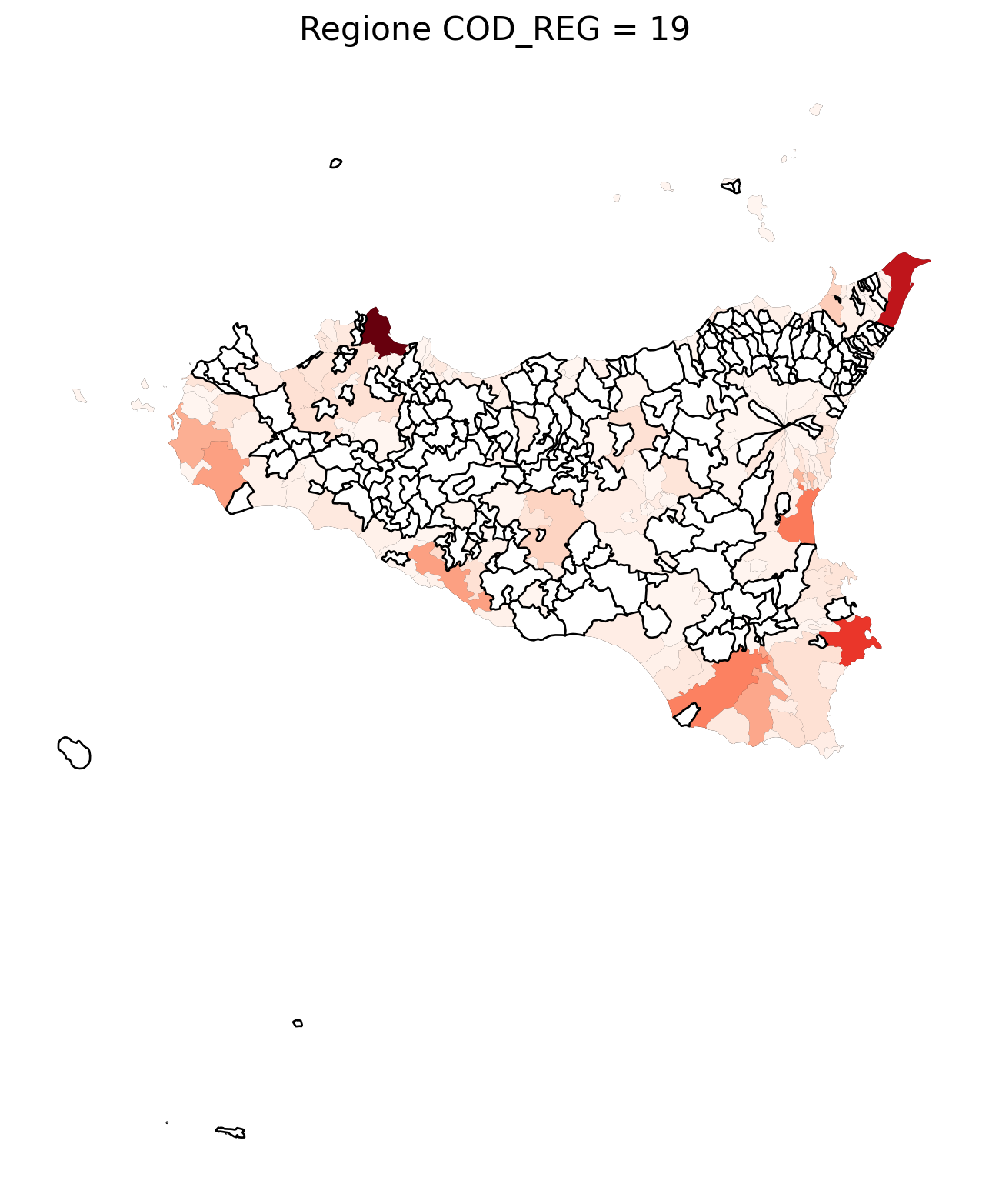
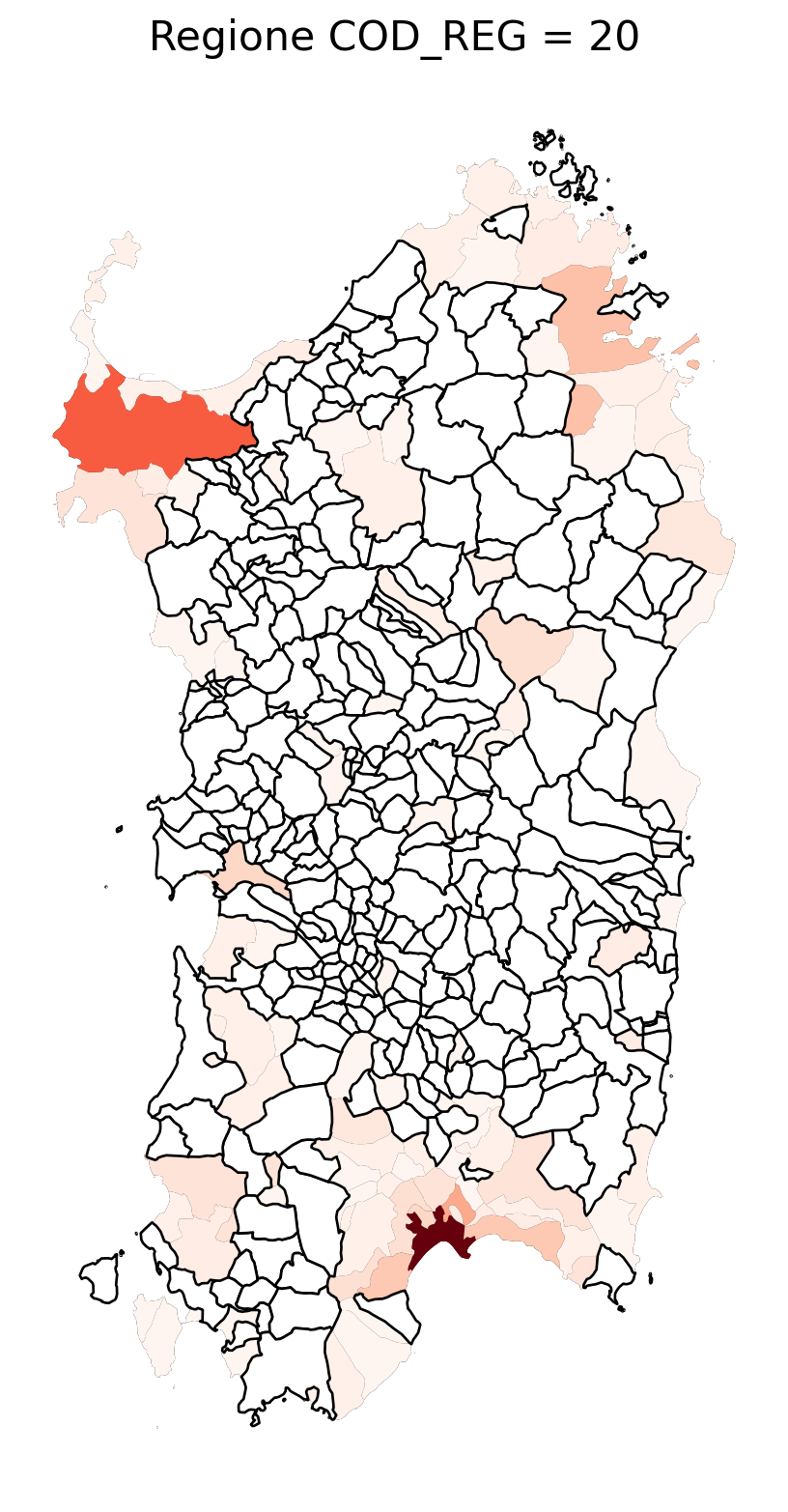
2.7 in azzurro con legenda range
import matplotlib.pyplot as plt
for i in range(1, 21):
# Filtra temporaneamente il DataFrame per ogni valore di COD_REG
temp_gdf = merged_gdf.query('COD_REG == @i')
# Crea una nuova figura per ogni grafico
fig, ax = plt.subplots(figsize=(10, 10))
# Traccia la mappa colorata in base alla colonna 'count'
temp_gdf.plot(
column='count',
cmap='Blues',
ax=ax,
legend=True,
edgecolor="grey", # Colore del contorno
linewidth=1, # Spessore del contorno
missing_kwds={
"color": "white", # Colore per i NaN
"edgecolor": "grey", # Contorno nero per i NaN
"linewidth": 0.5 # Spessore coerente anche per i NaN
}
)
# Aggiungi titolo e dettagli
ax.set_title(f"Regione COD_REG = {i}", fontsize=16)
ax.axis('off') # Rimuovi assi per un aspetto più pulito
# Mostra la figura
plt.show()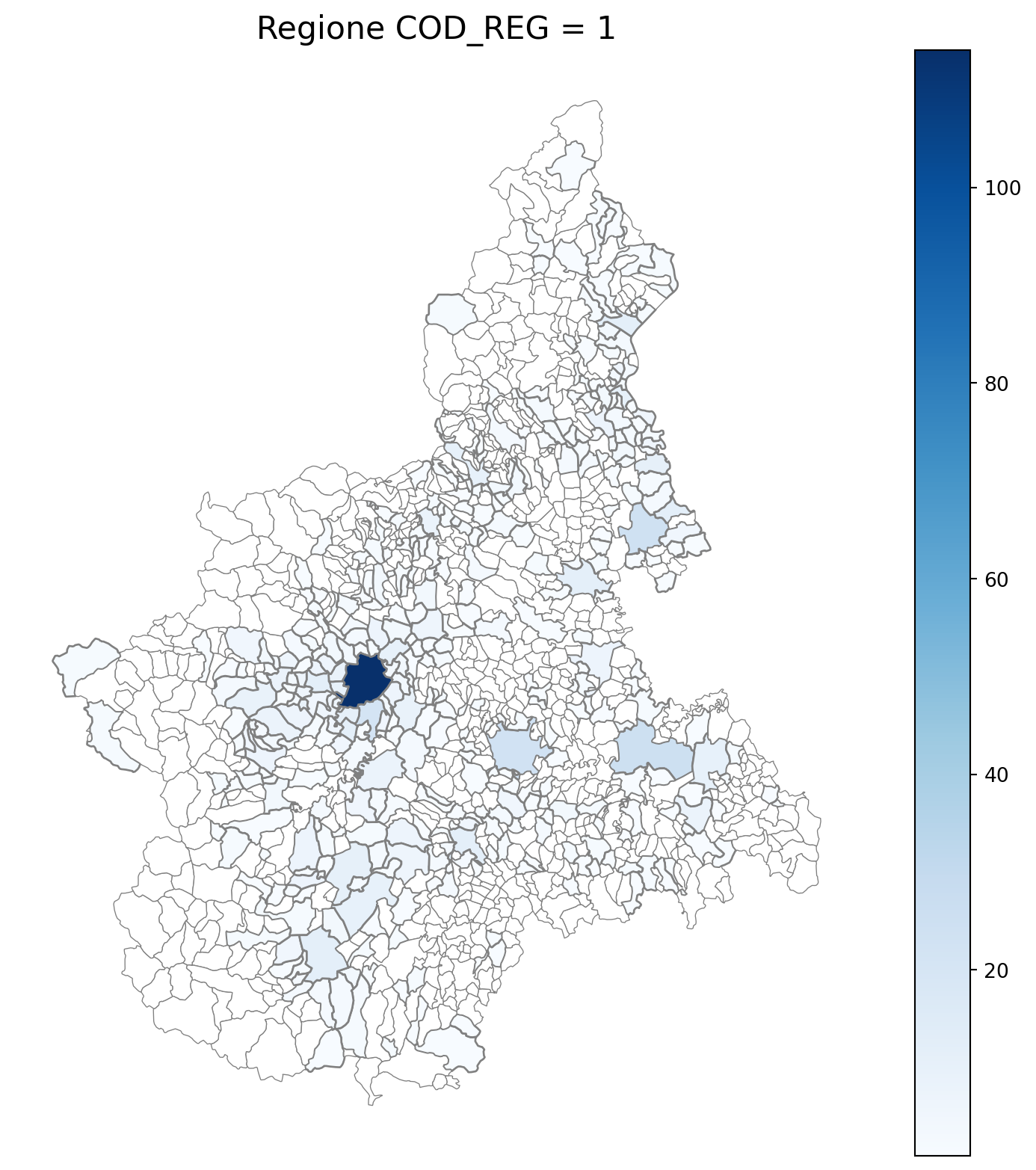
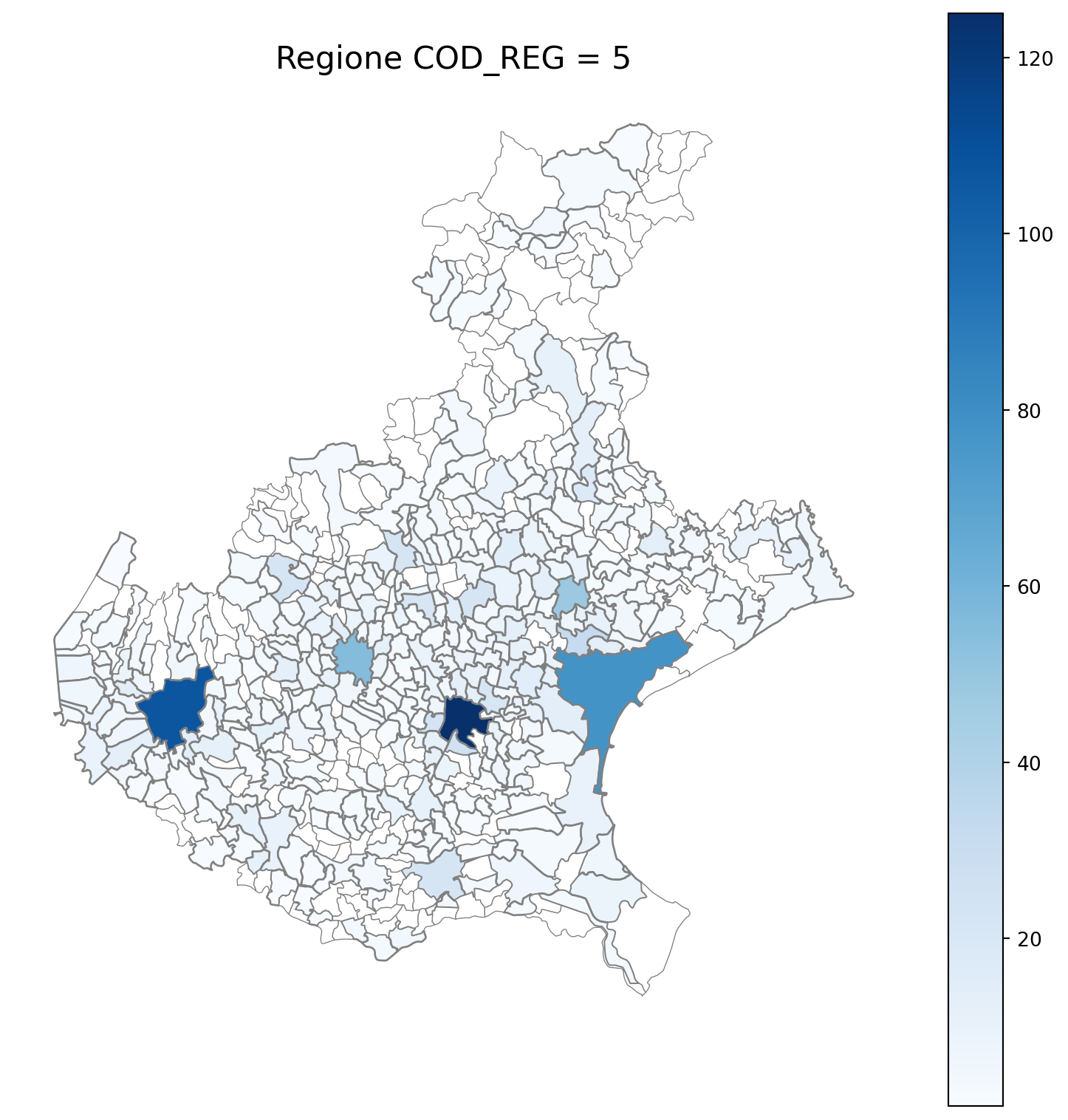
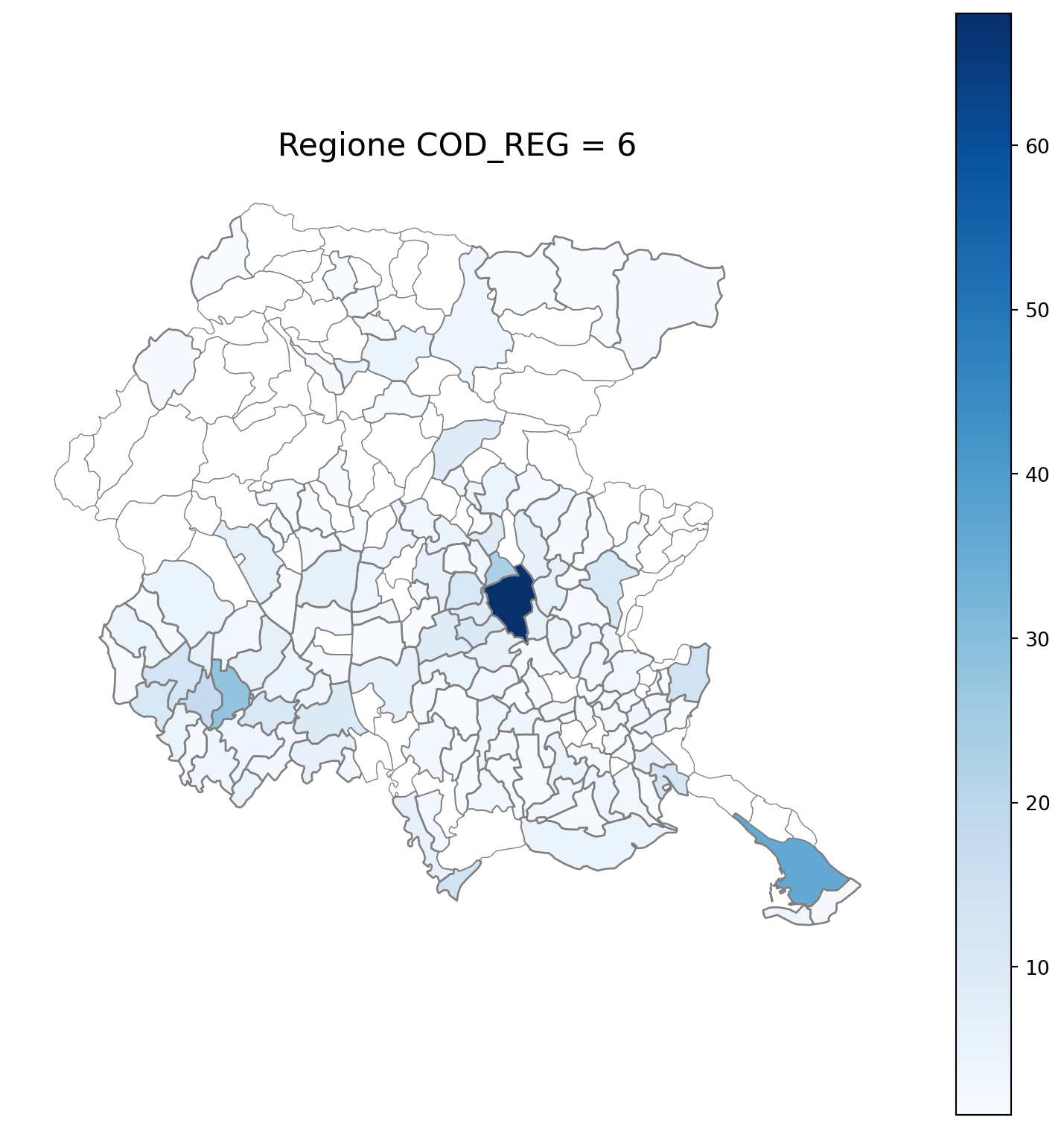
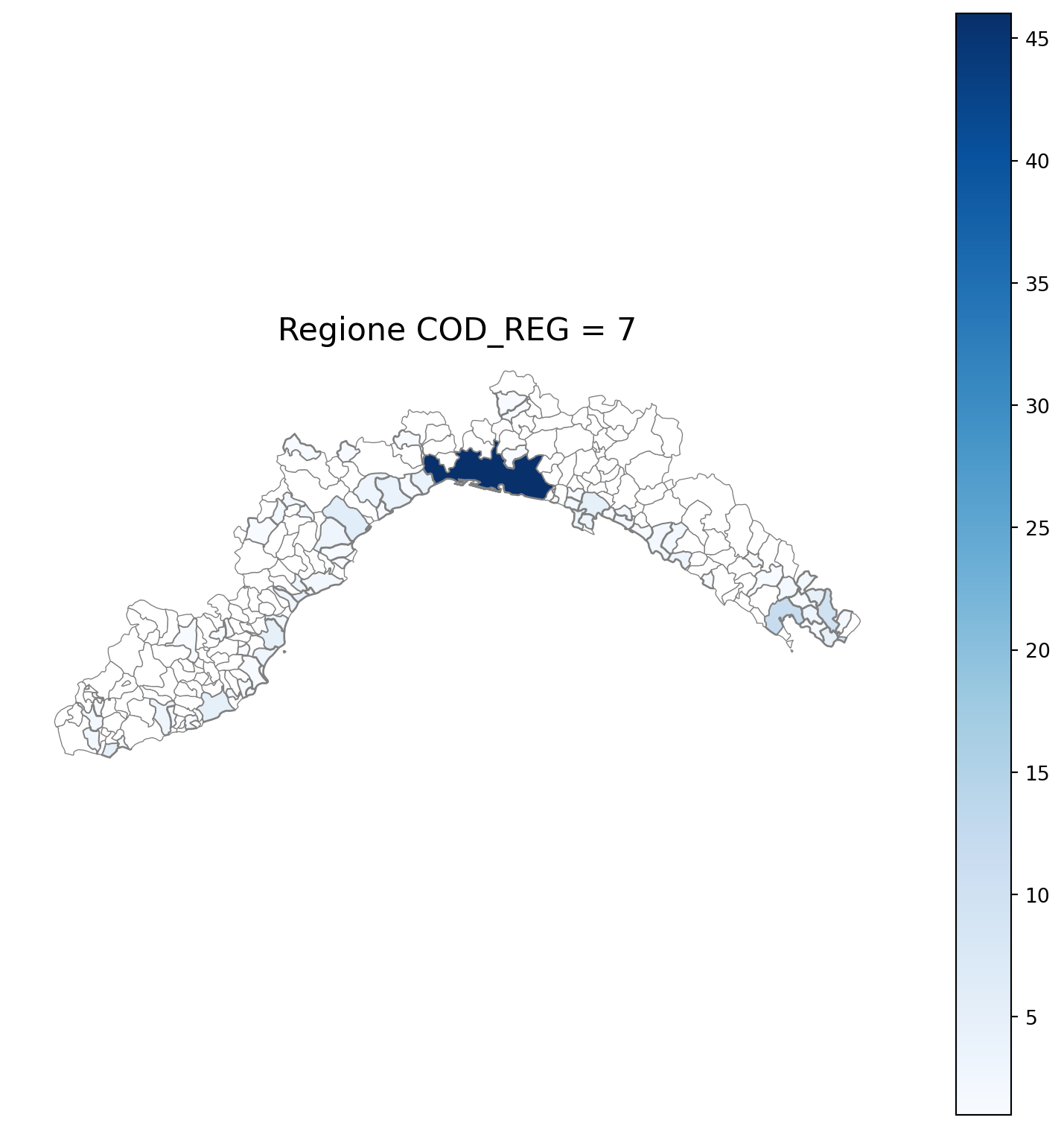
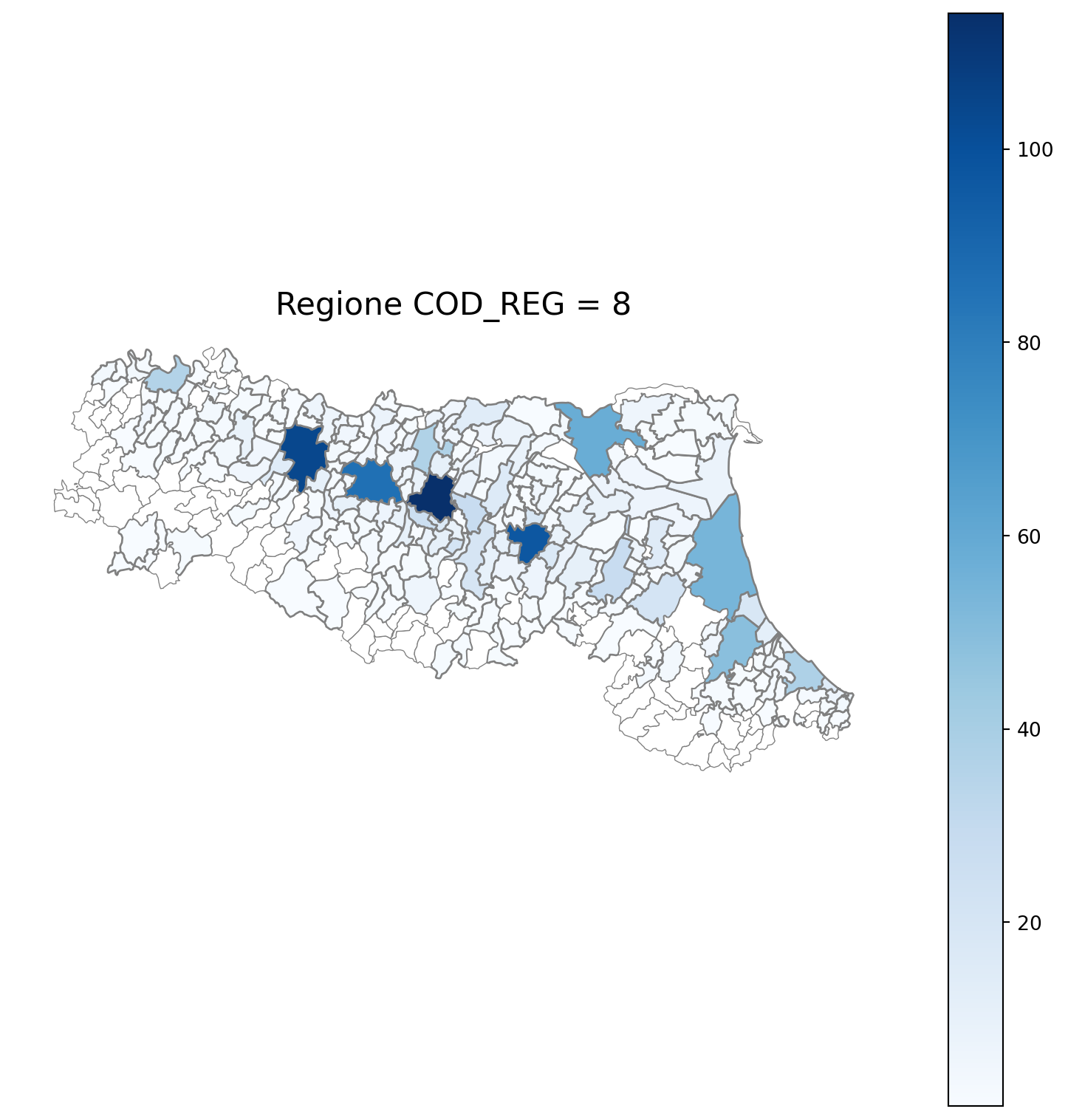
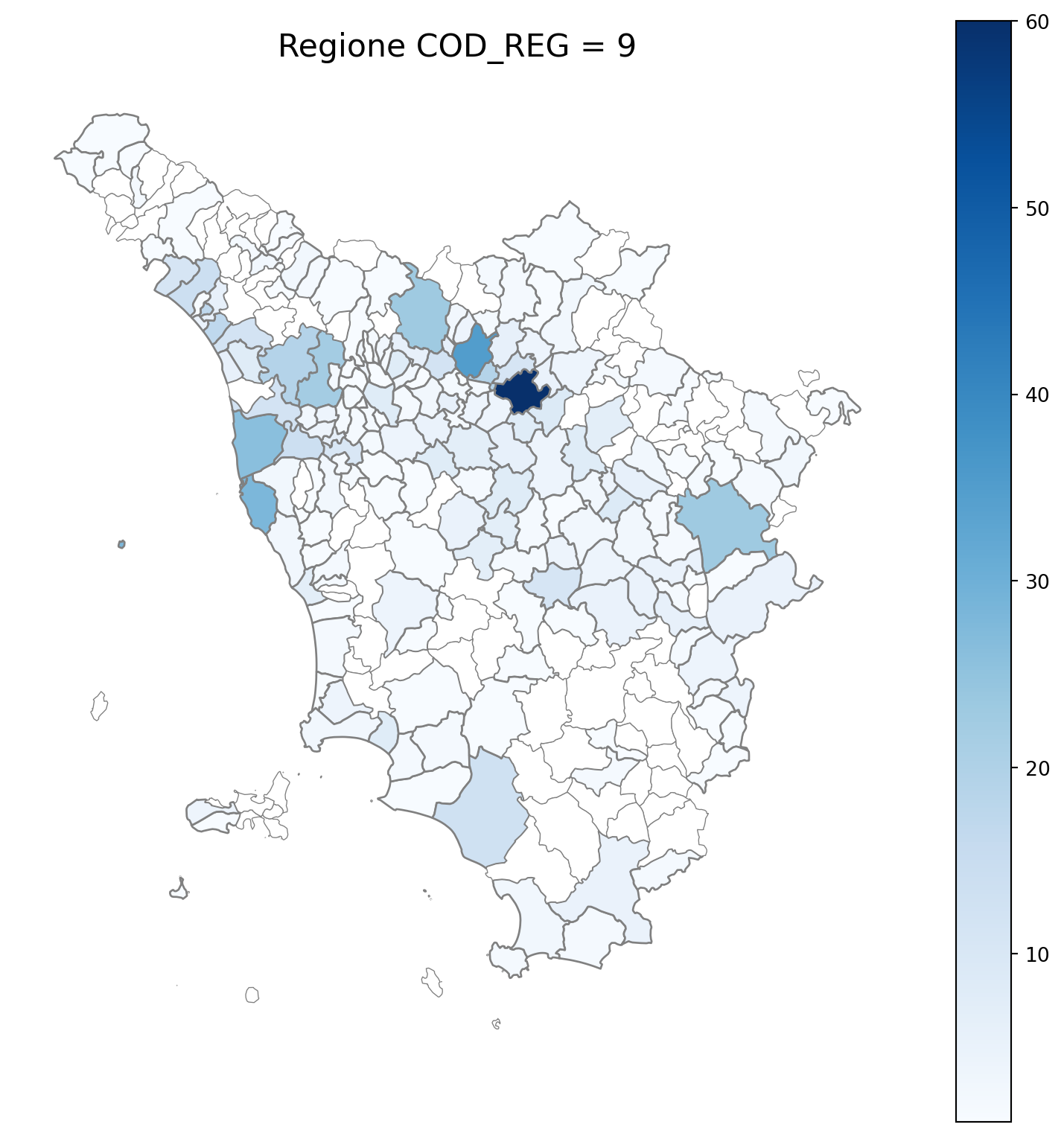
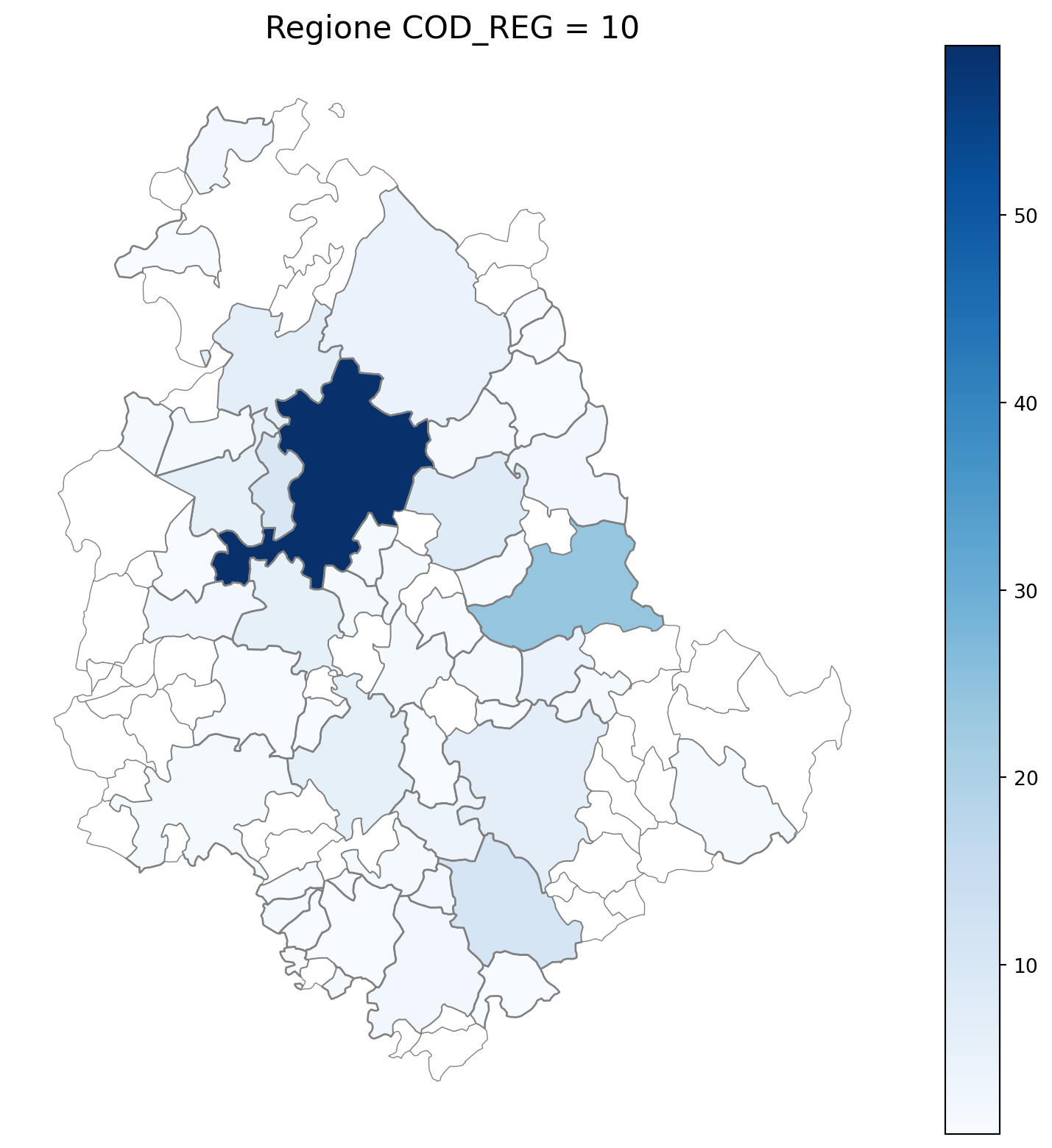
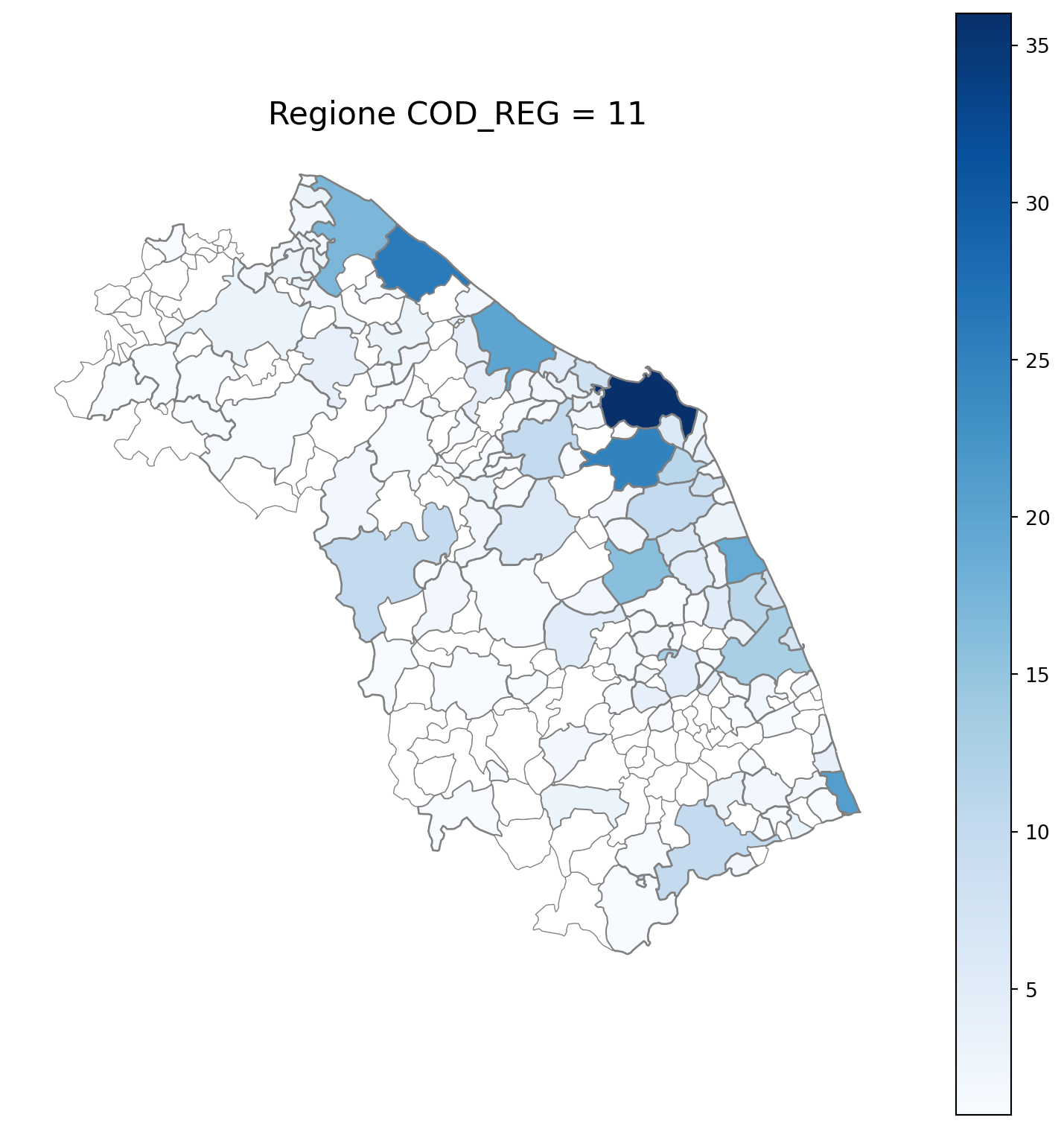
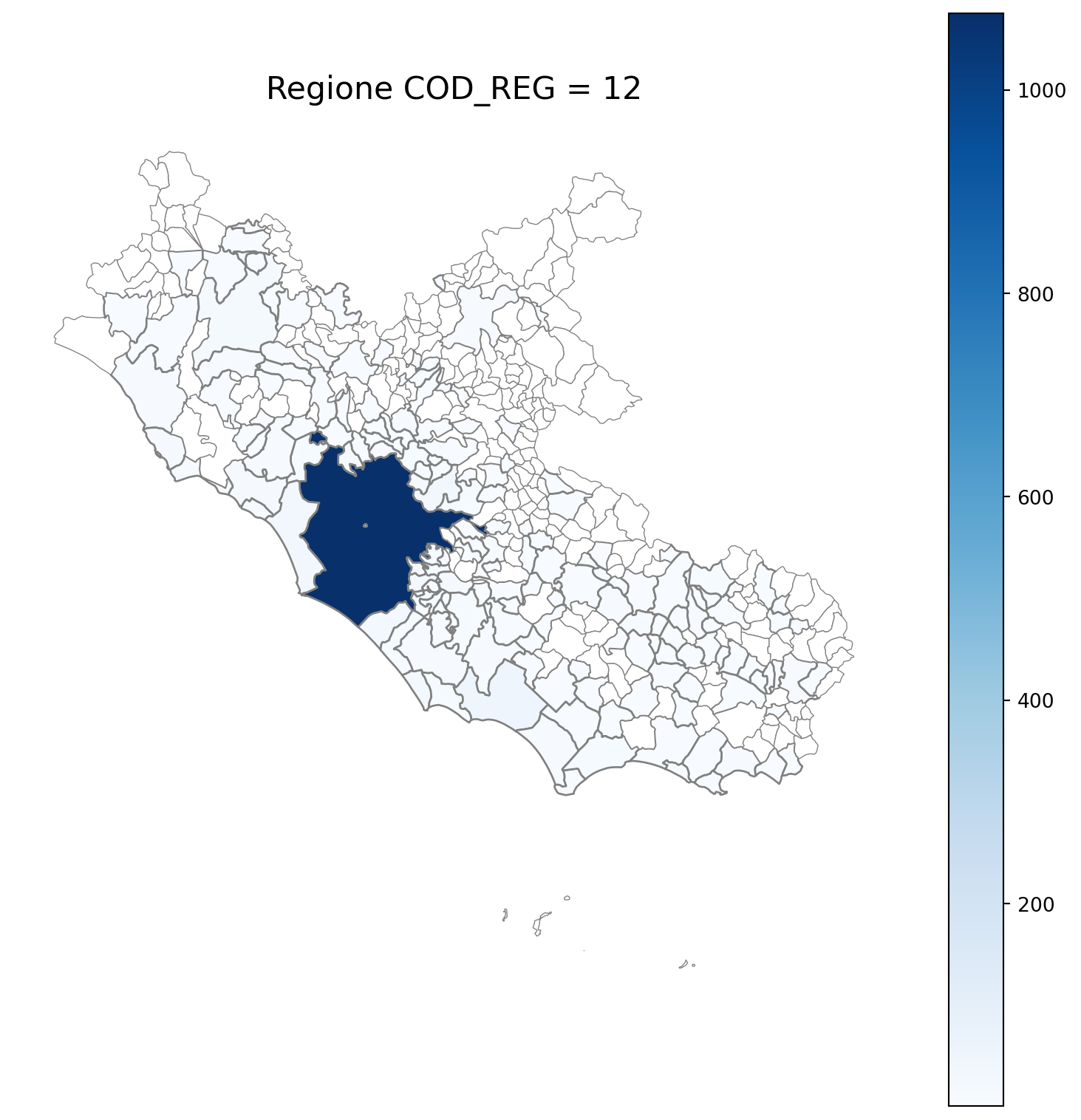
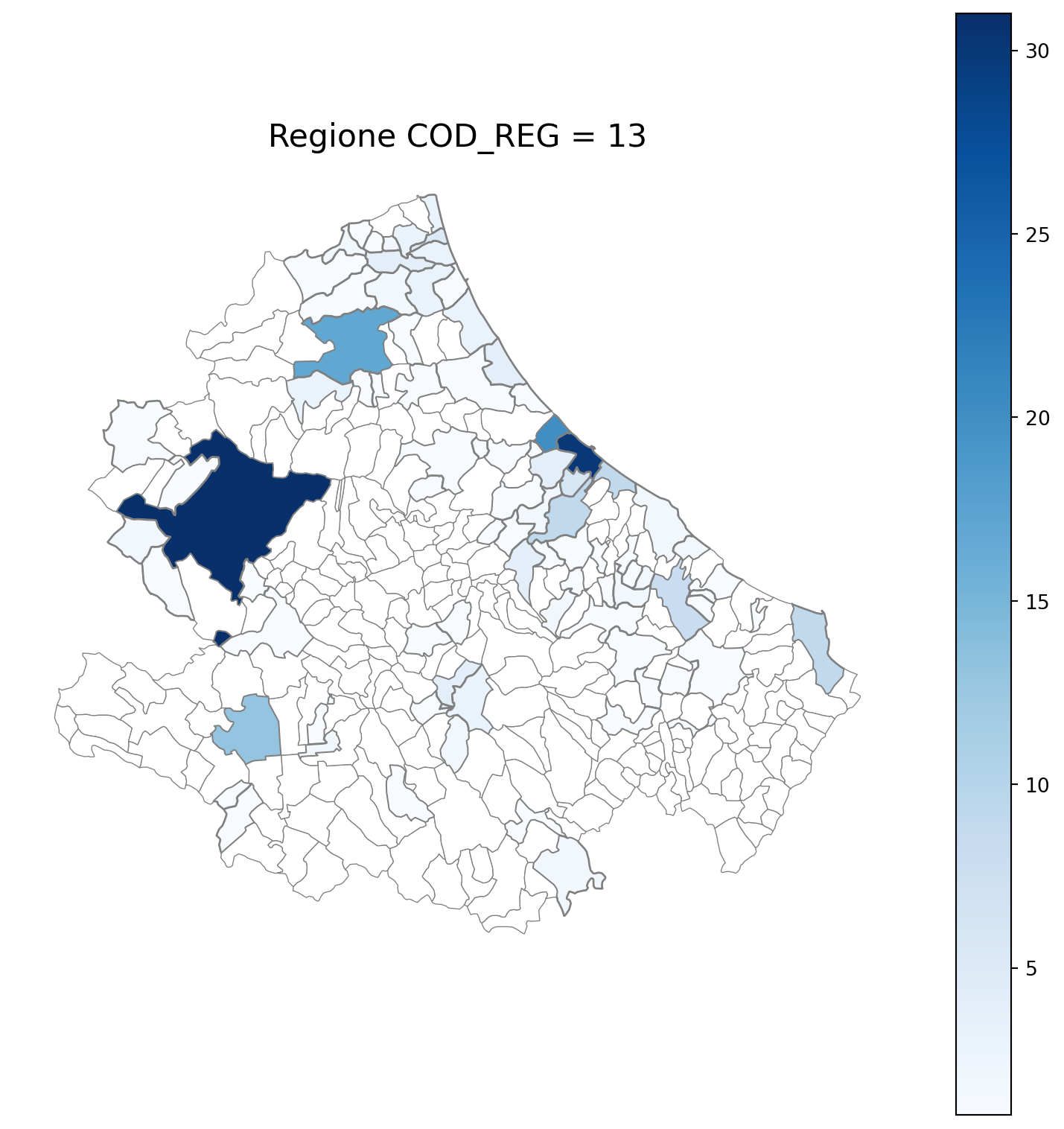
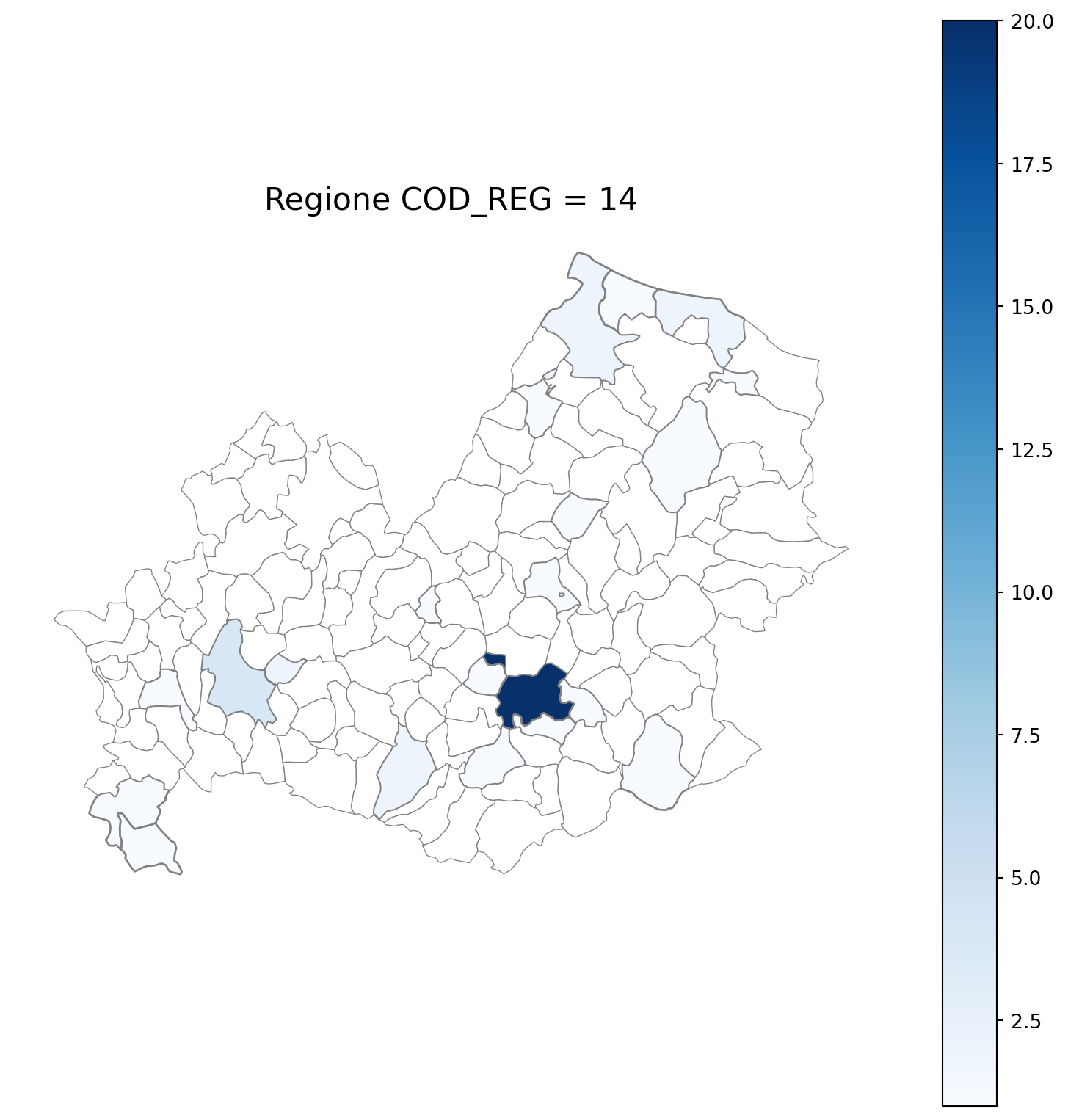
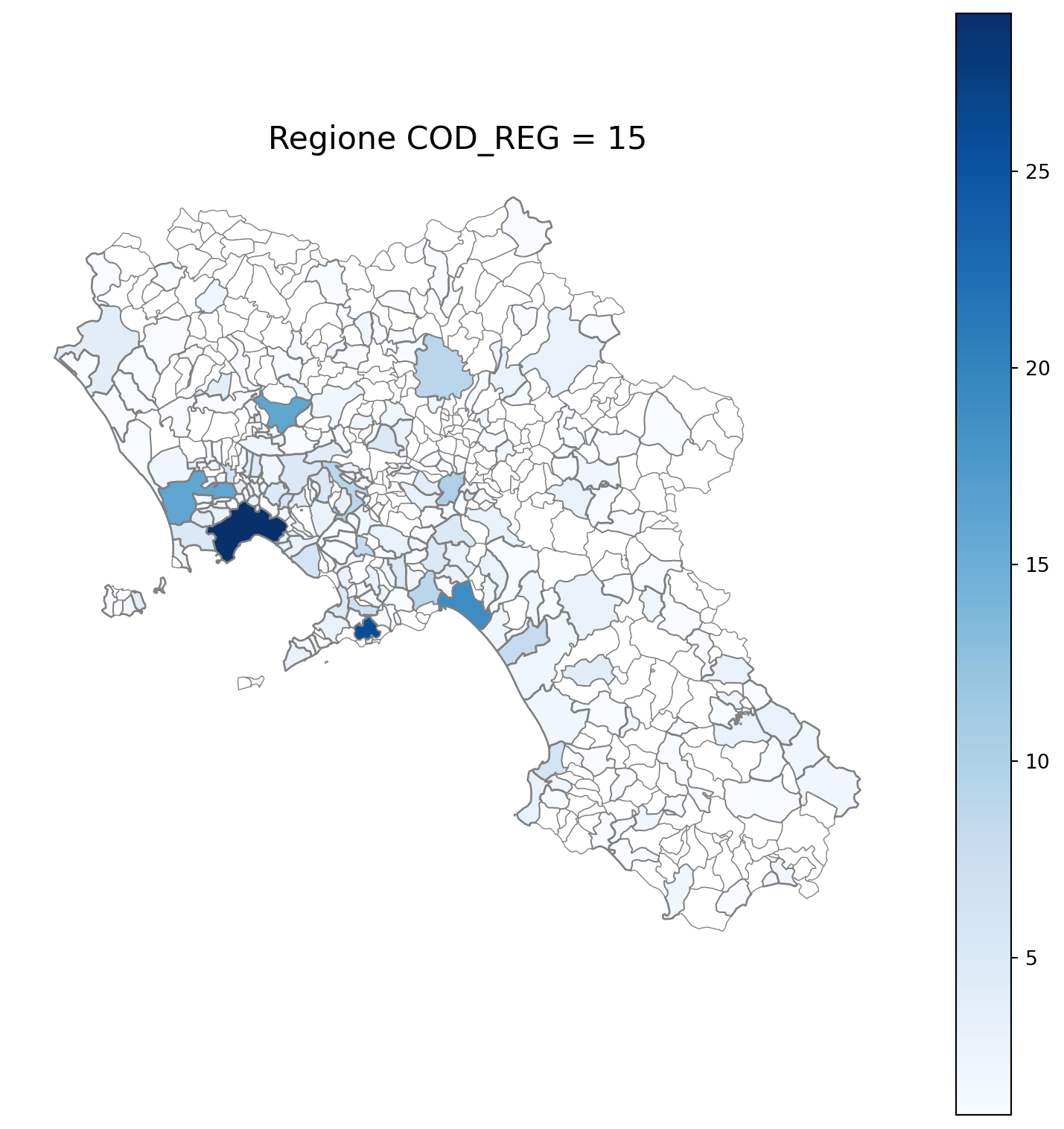
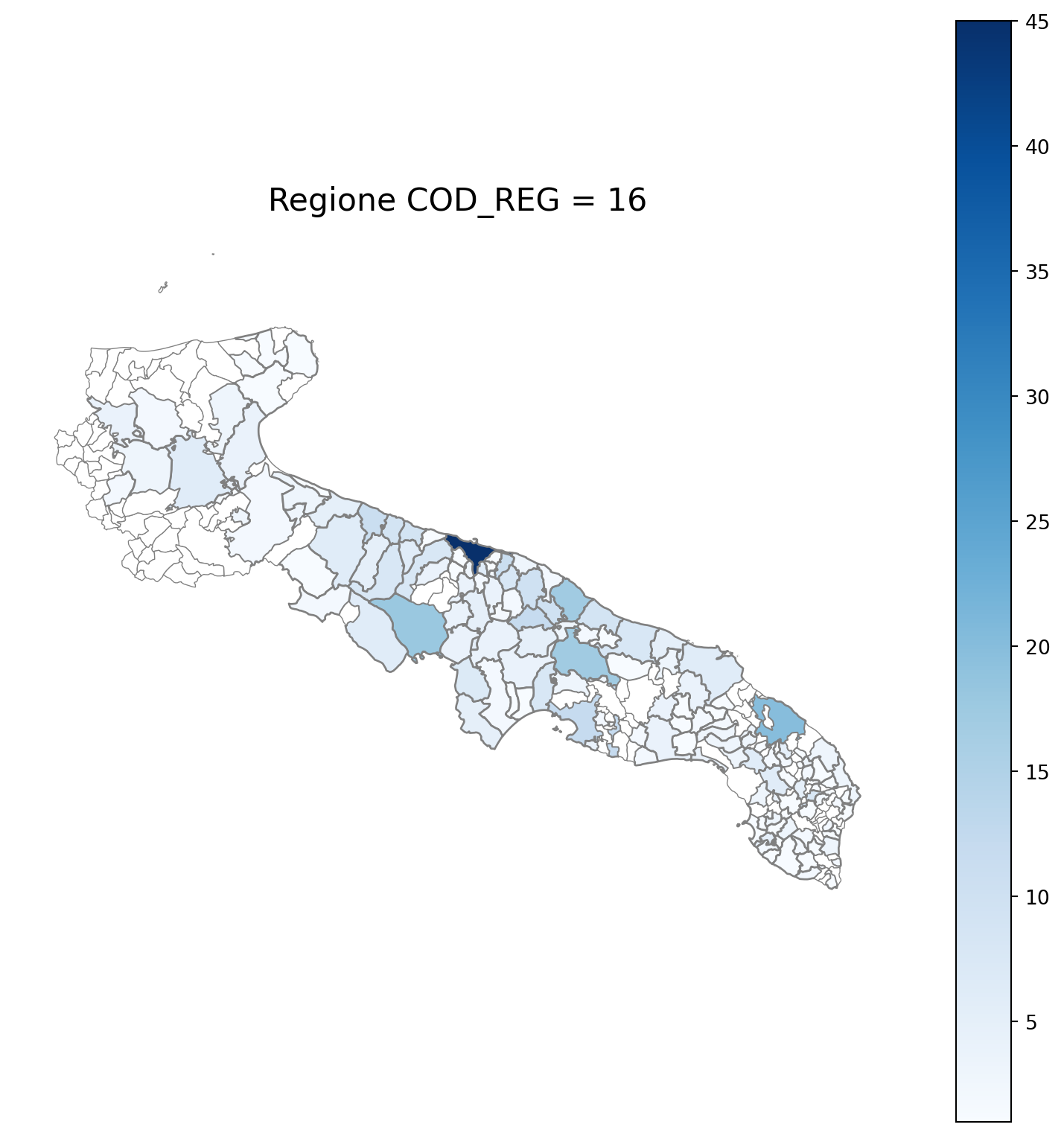
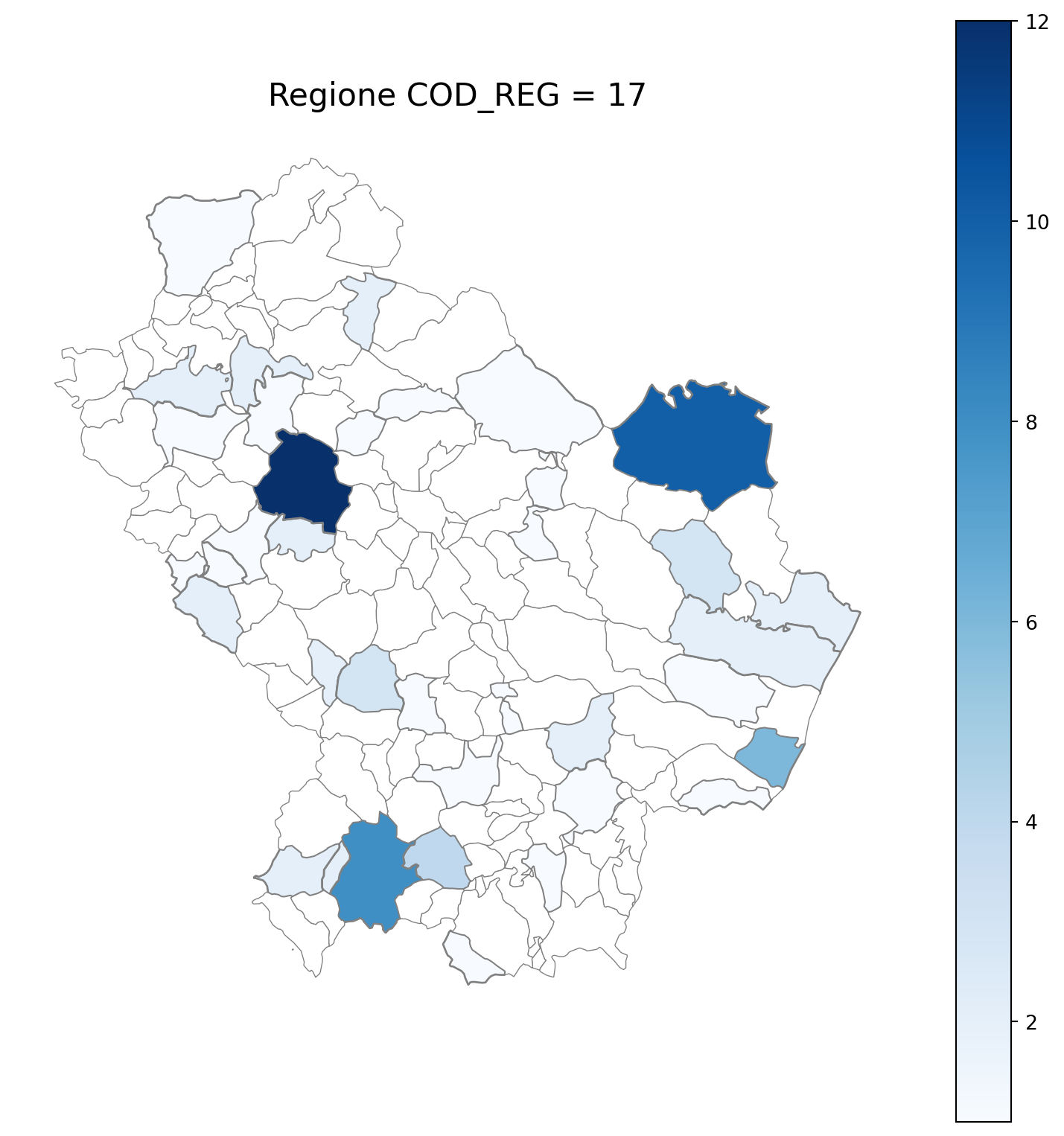
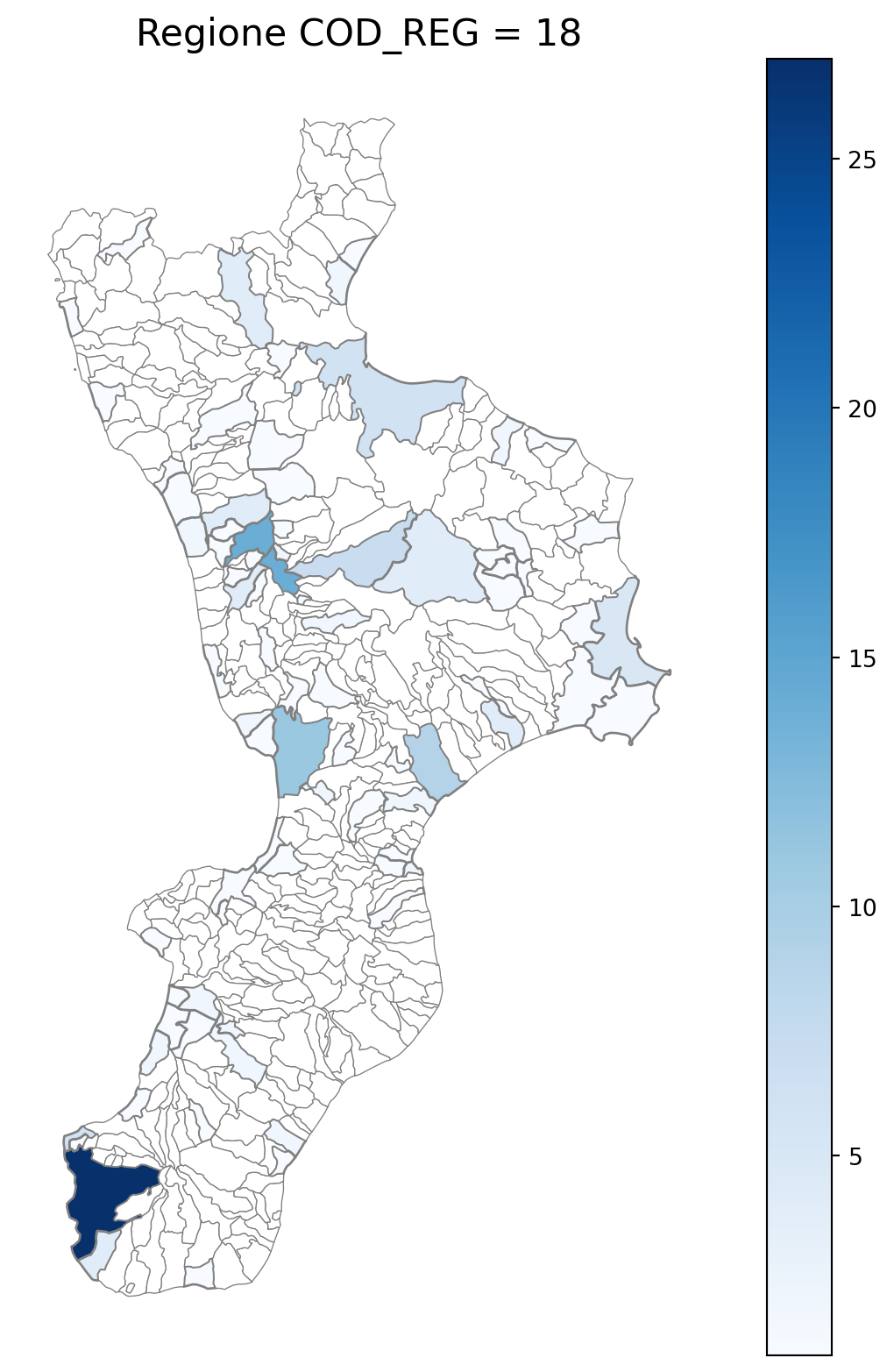
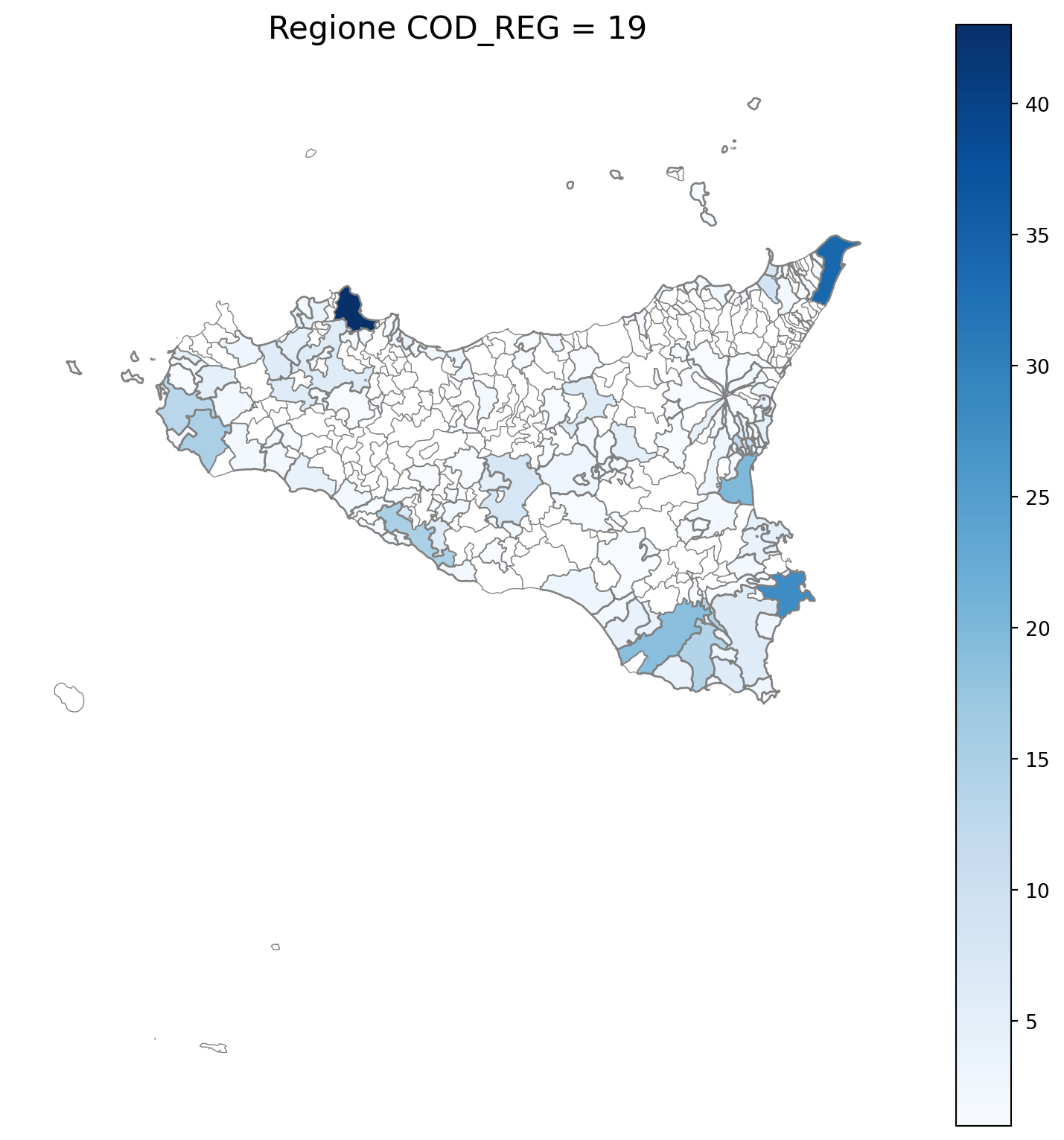
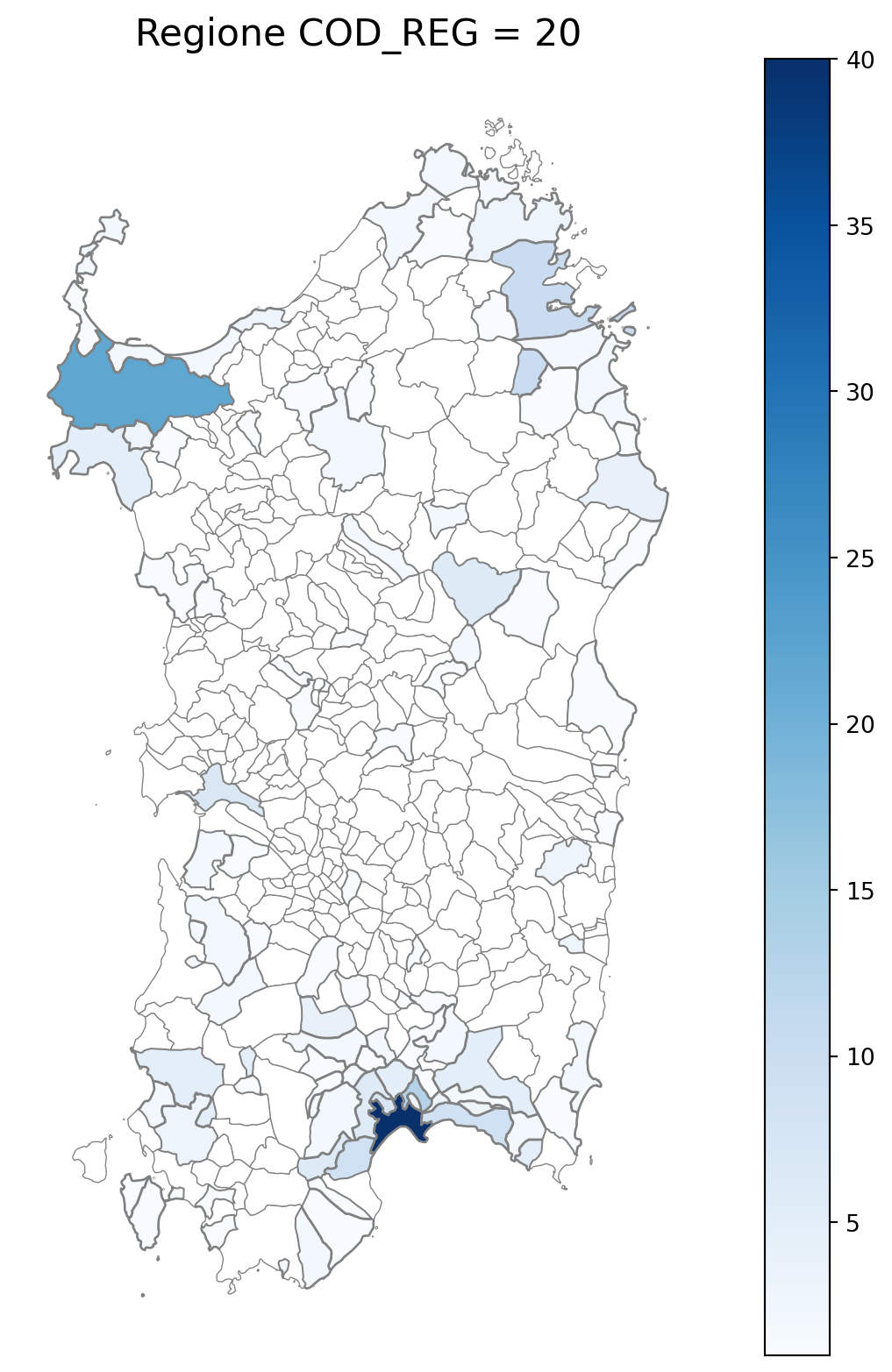
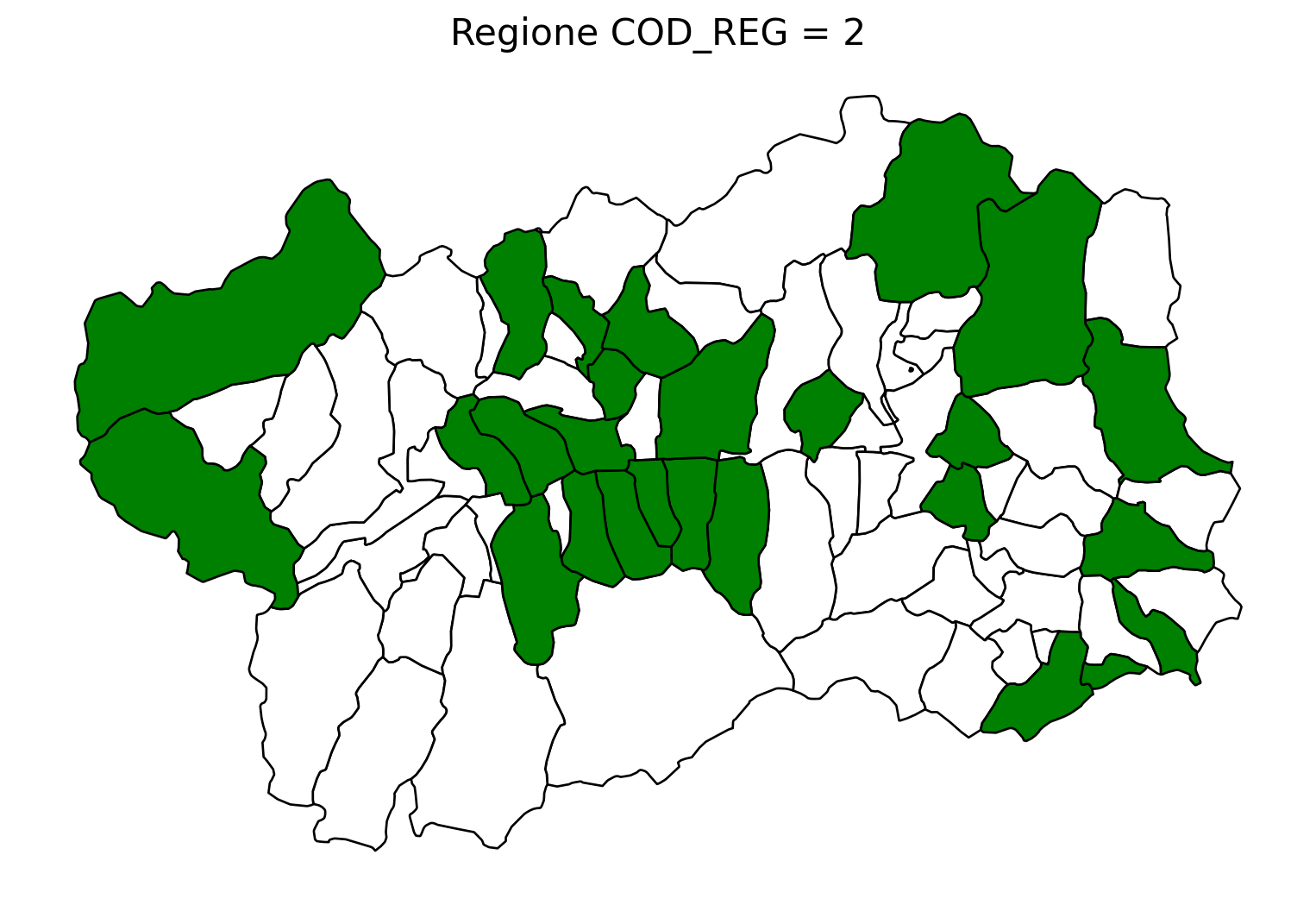
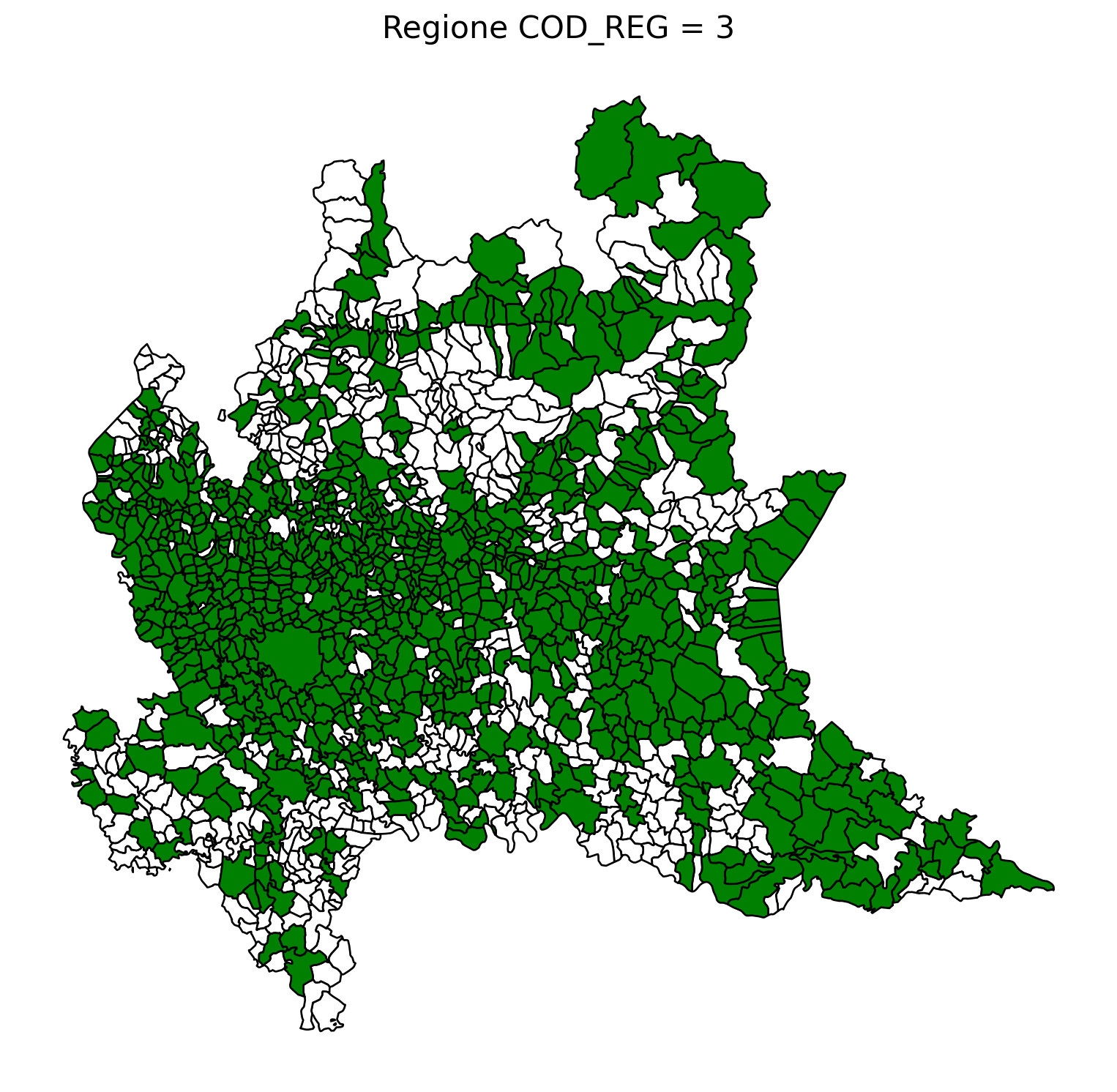
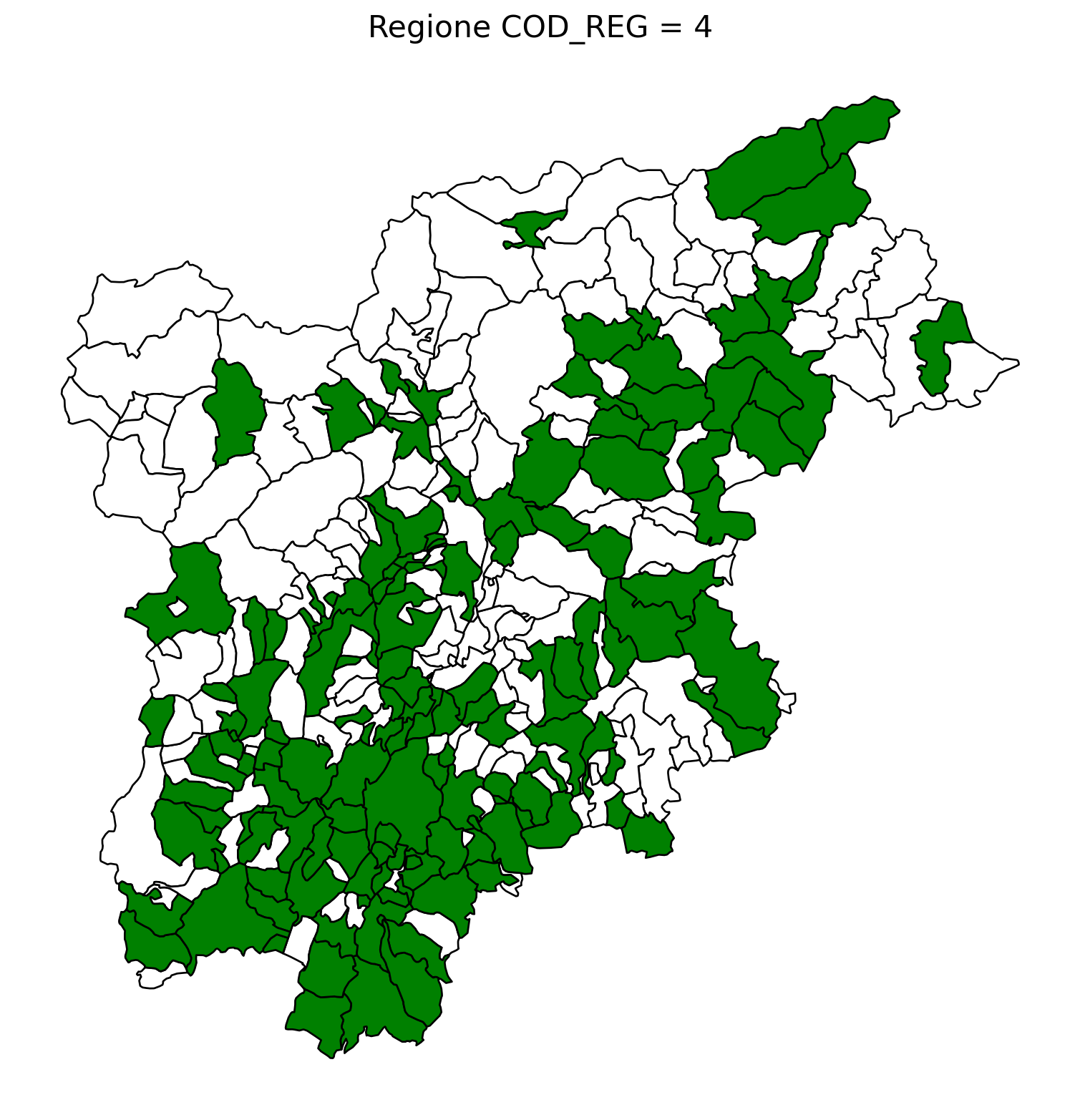
2.8 comuni presenti (in verde) o assenti
comuni = result2.groupby('COMUNE')['COMUNE'].count().reset_index(name='count')
df1 = gpd.read_file('D:/files/csv/Shapefile/Limiti01012023_g/Com01012023_g/Com01012023_g_WGS84.shp')
df1['COMUNE'] = df1['COMUNE'].str.upper()
merged_gdf = df1.merge(comuni, left_on='COMUNE', right_on='COMUNE', how='left')
# merged_gdf.to_csv('D:\\files\\csv\\20241212_Colonnine elettriche\\merged.csv', sep='|', index = False)
for i in range(1, 21):
# Filtra temporaneamente il DataFrame per ogni valore di COD_REG
temp_gdf = merged_gdf.query('COD_REG == @i')
# Crea una nuova figura per ogni grafico
fig, ax = plt.subplots(figsize=(10, 10))
# Poligoni con valori NaN (bianco con contorno nero)
temp_gdf[temp_gdf['count'].isna()].plot(
ax=ax,
color='white', # Colore interno bianco
edgecolor='black', # Contorno nero
linewidth=1 # Spessore contorno uniforme
)
# Poligoni con valori validi (verde con contorno nero)
temp_gdf[temp_gdf['count'].notna()].plot(
ax=ax,
color='green', # Colore interno verde
edgecolor='black', # Contorno nero
linewidth=1 # Spessore contorno uniforme
)
# Aggiungi titolo e dettagli
ax.set_title(f"Regione COD_REG = {i}", fontsize=16)
ax.axis('off') # Rimuovi gli assi per un aspetto più pulito
# Salva l'immagine con il nome del valore COD_REG
# plt.savefig(f"D:/cod_reg_{i}.png", dpi=300, bbox_inches='tight')
# Chiudi la figura per liberare memoria
# plt.close(fig)
plt.show()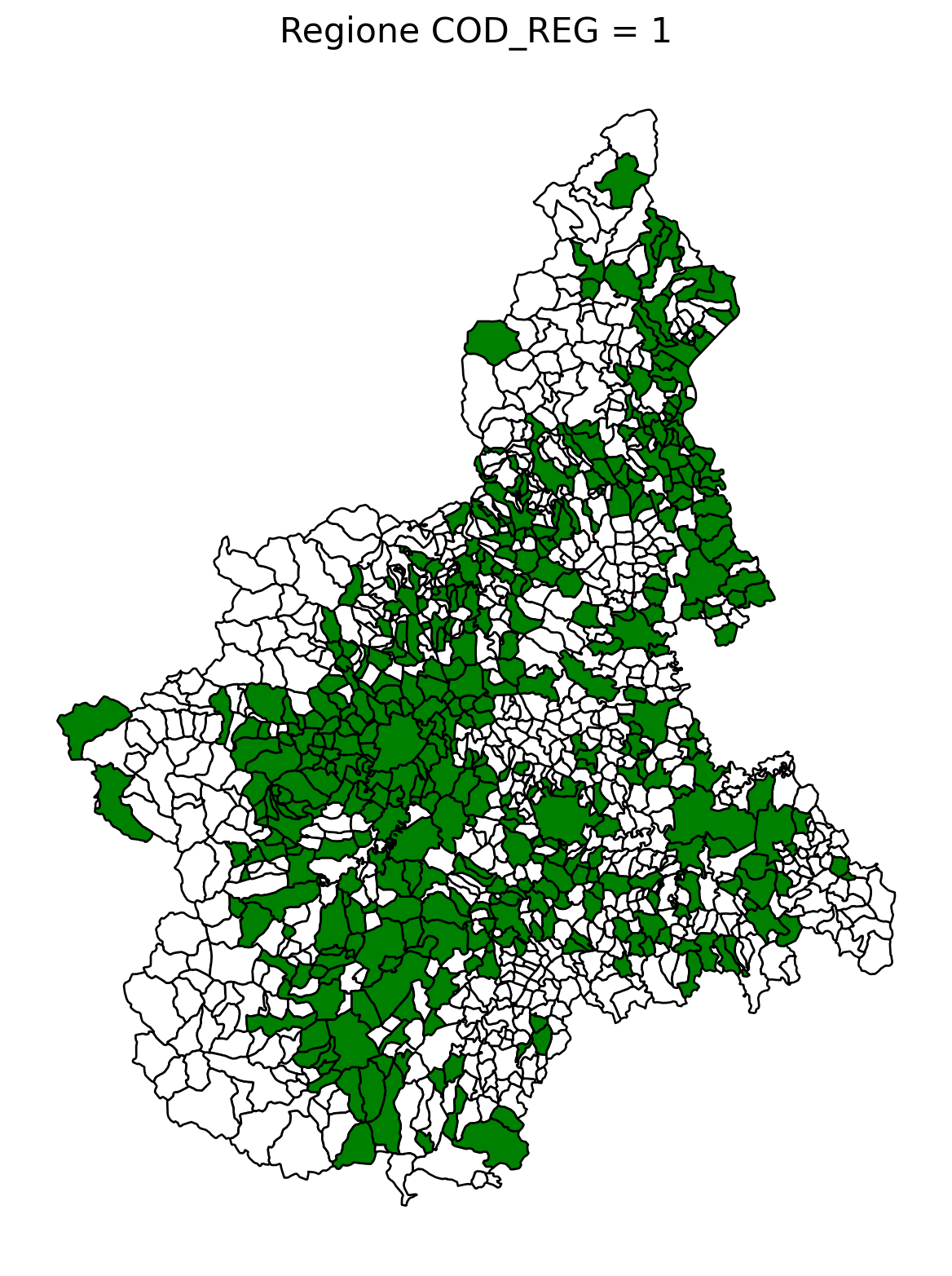
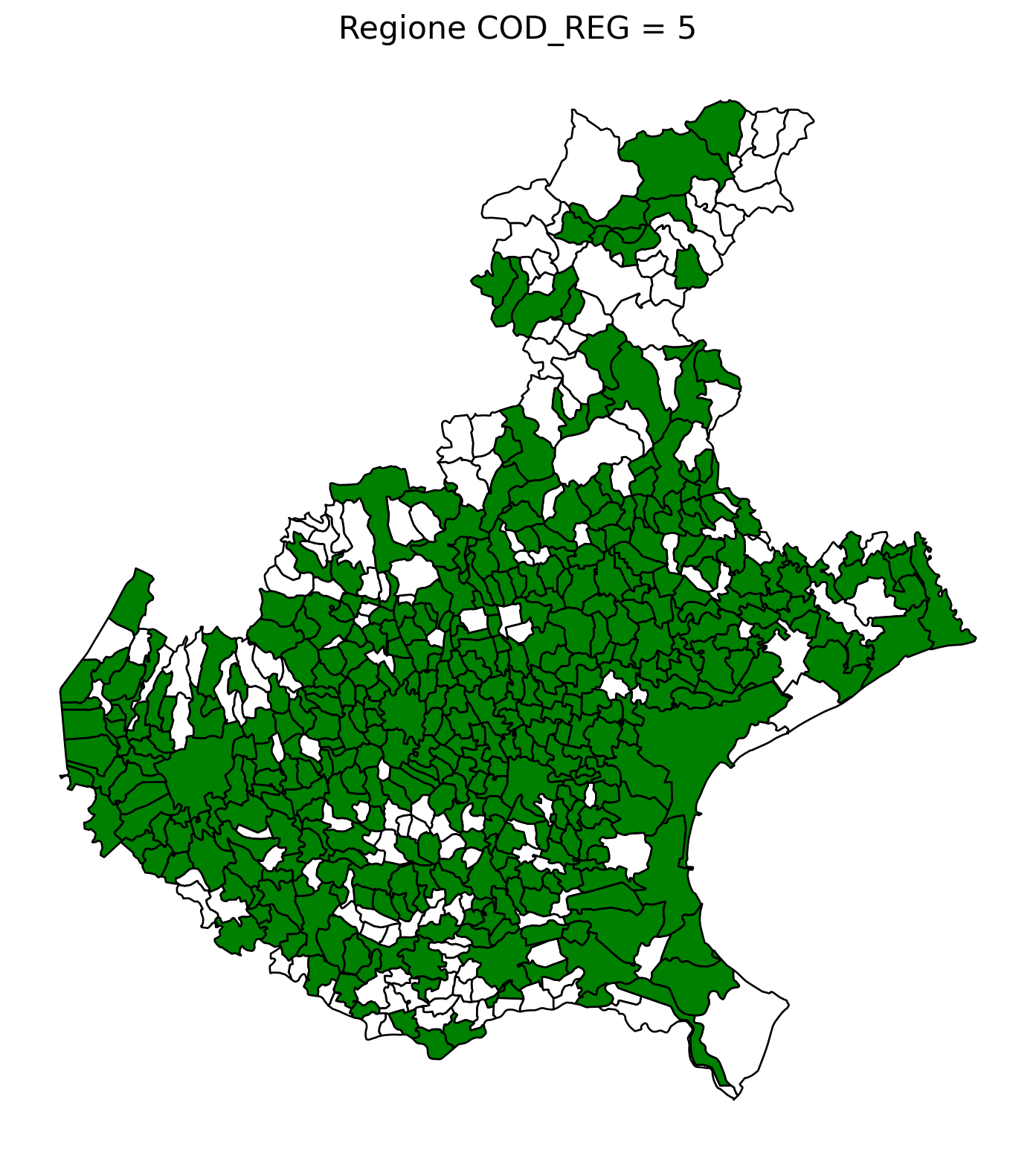
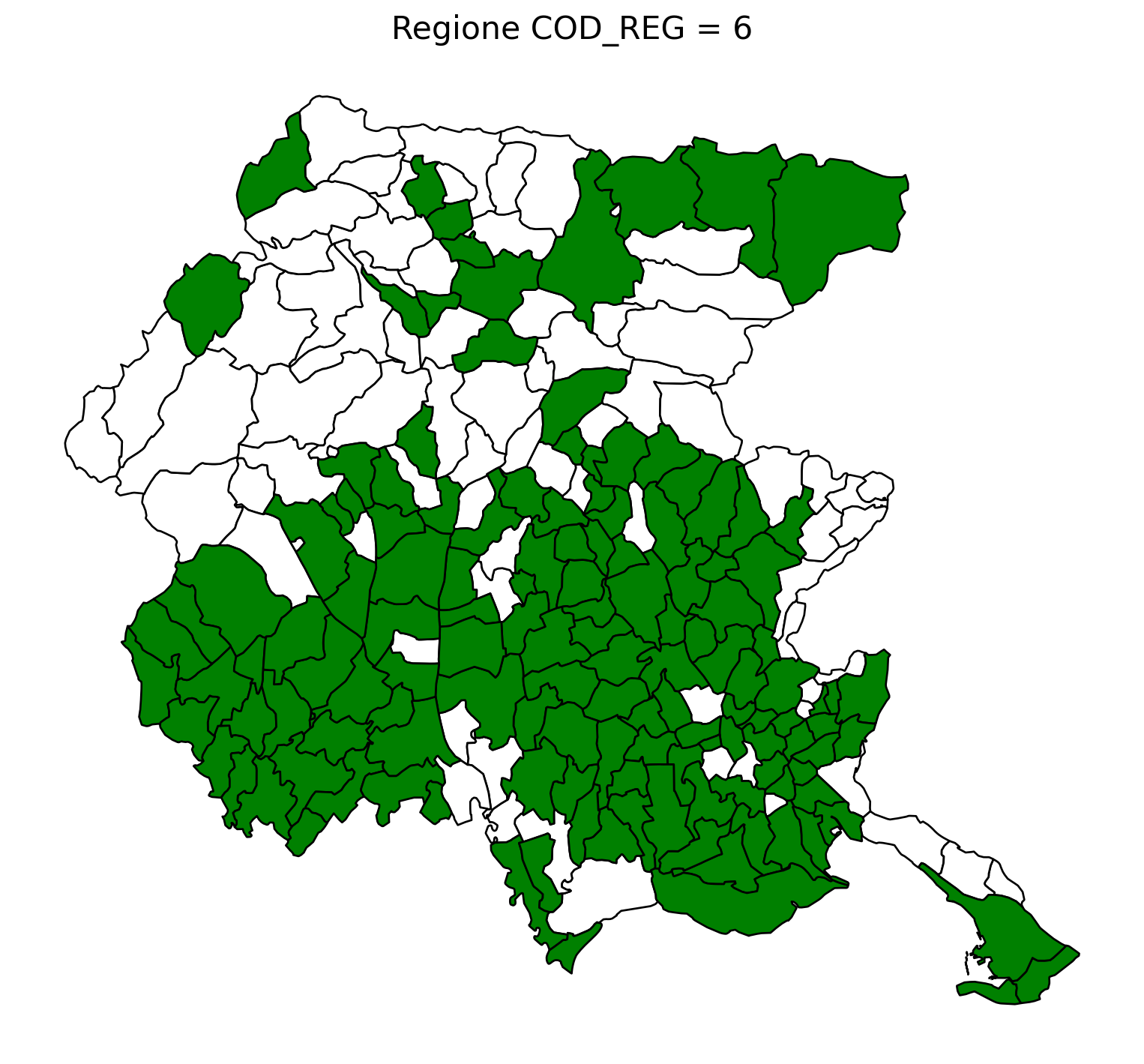
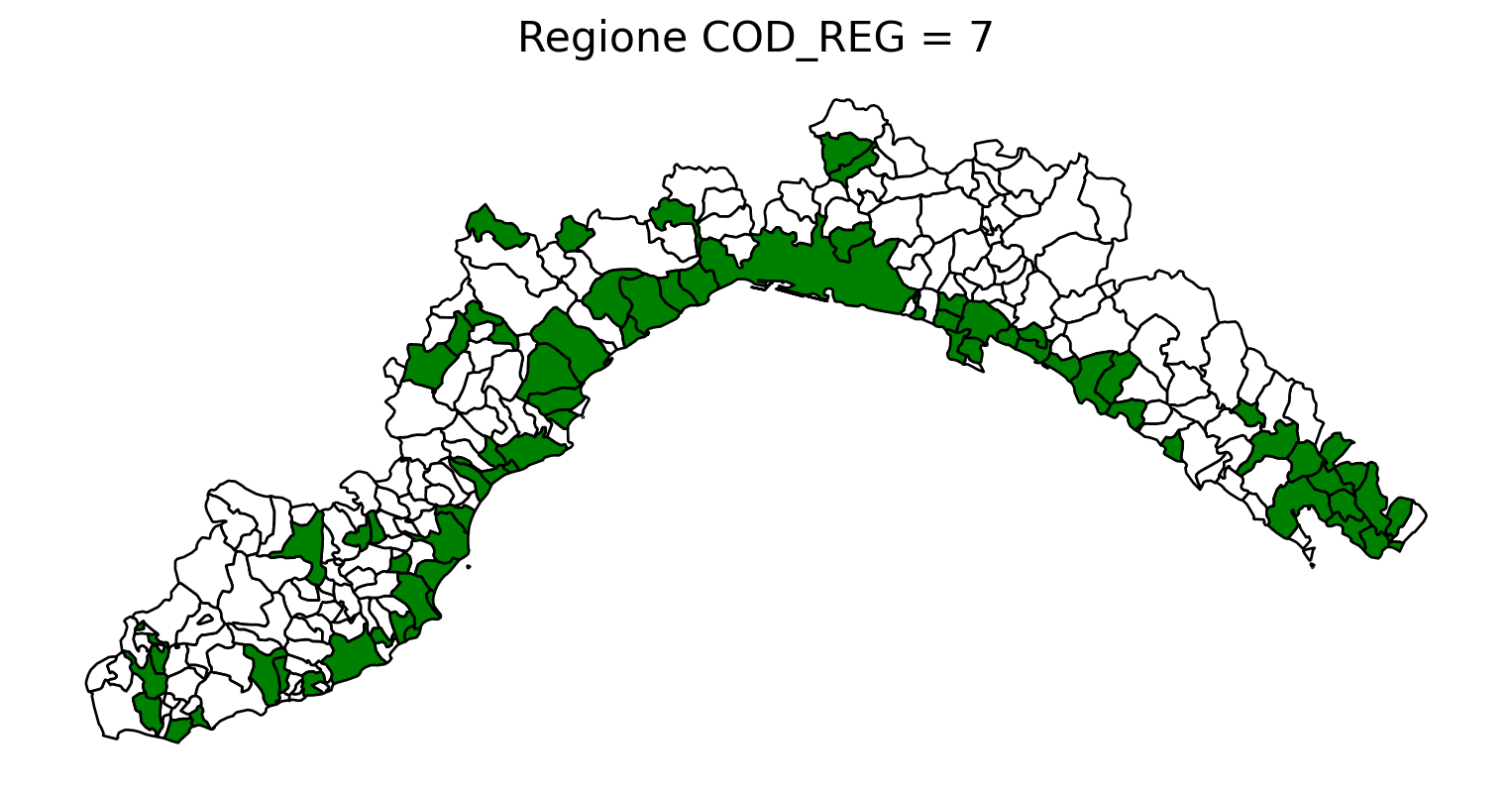
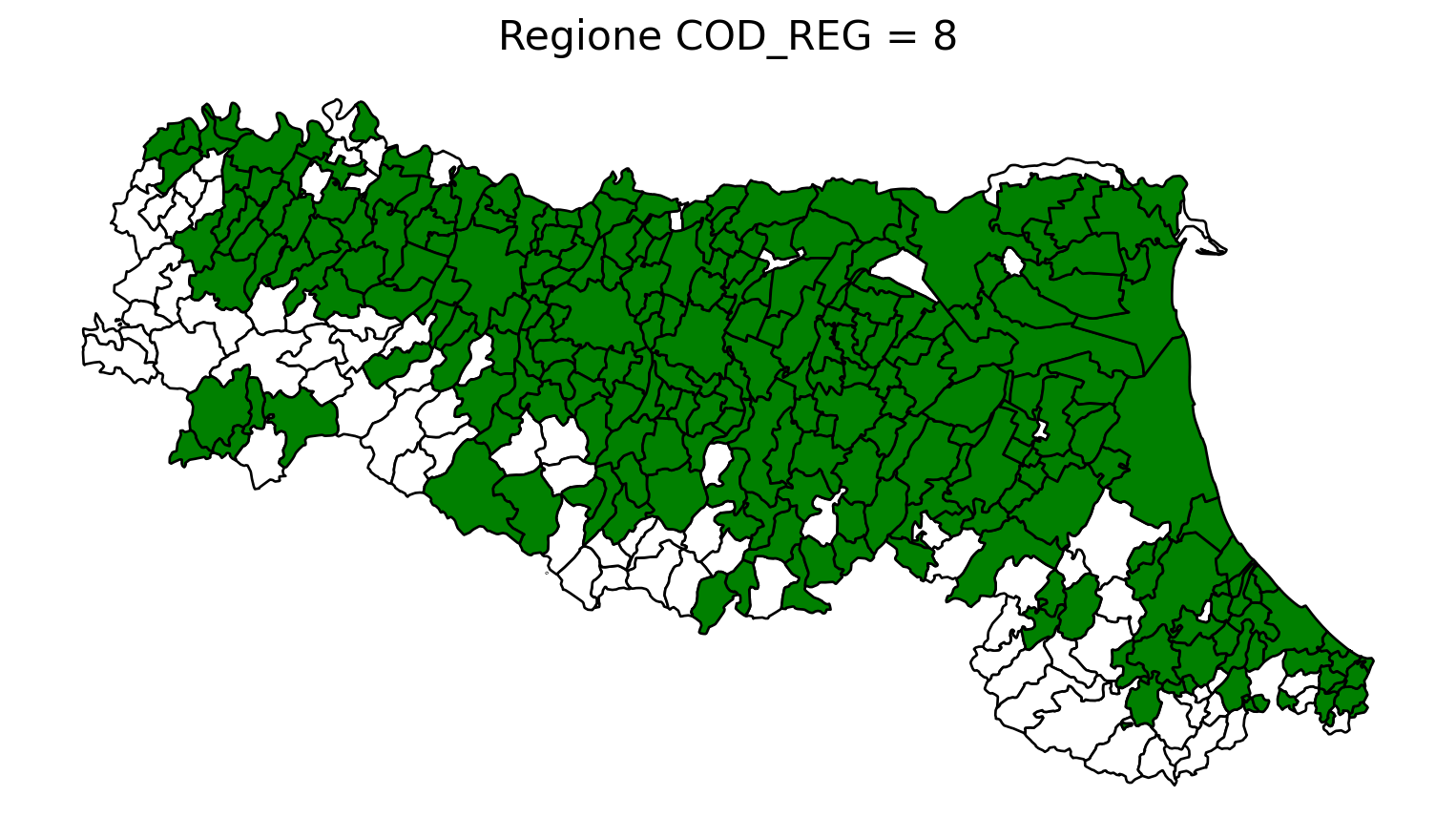
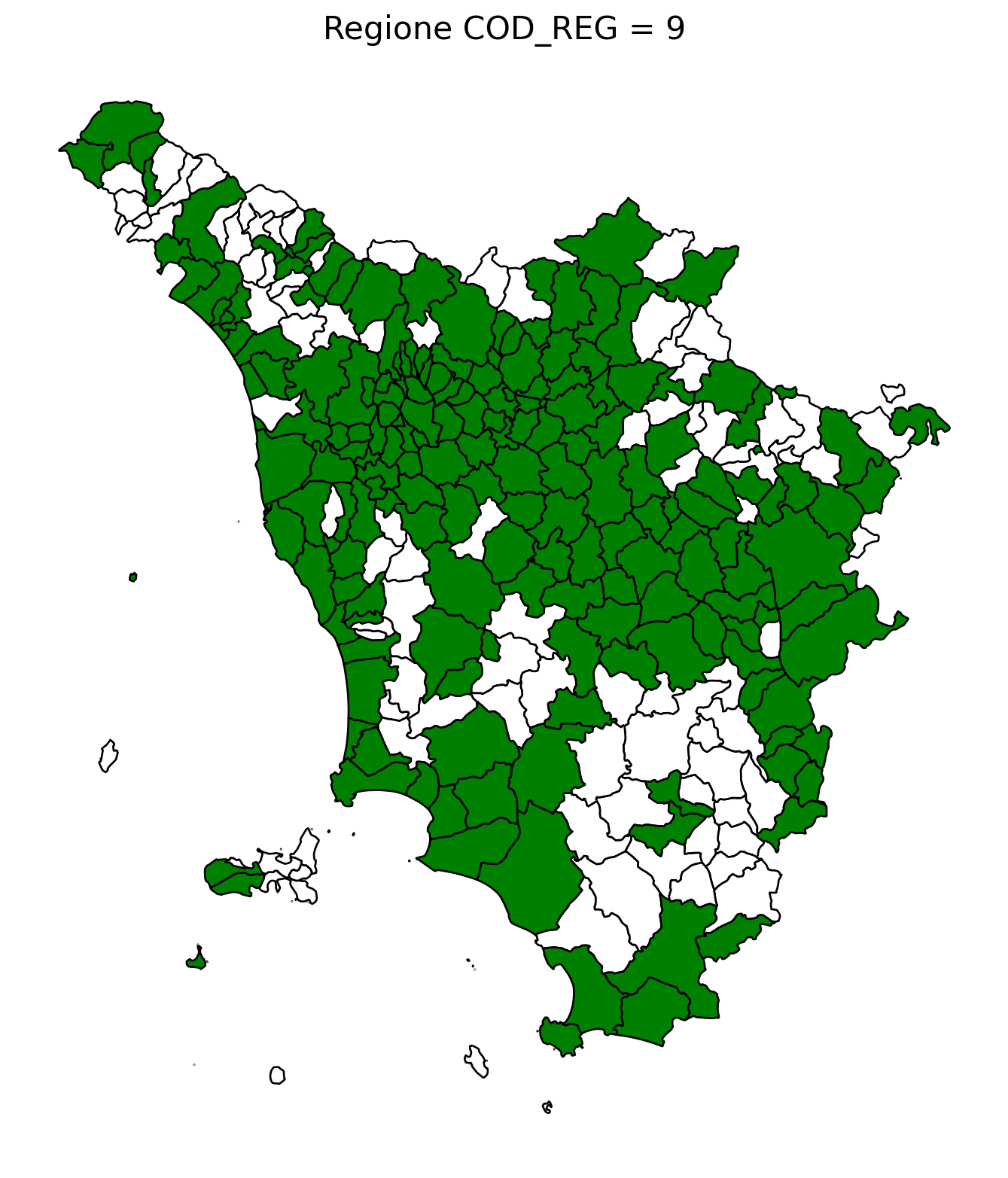
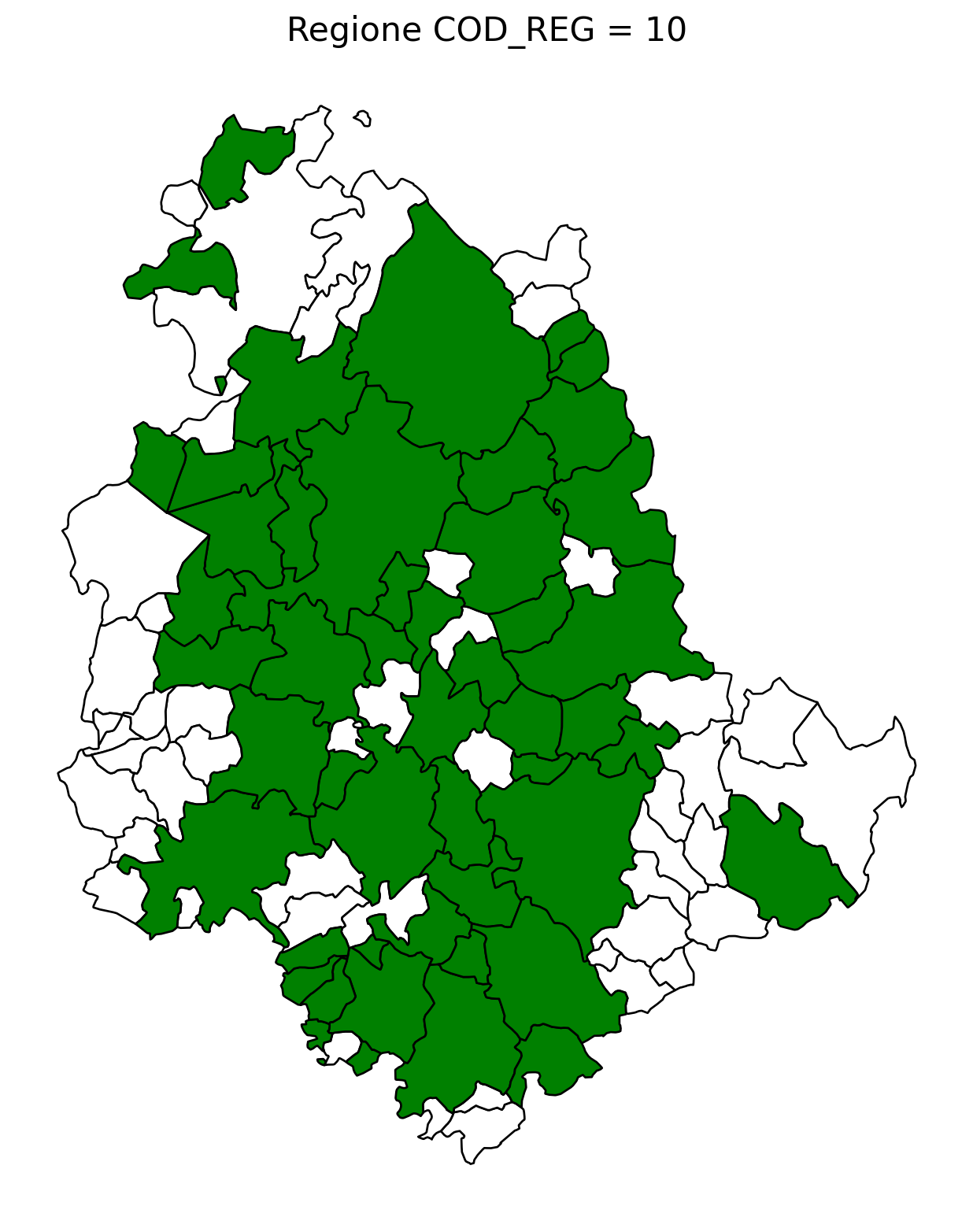
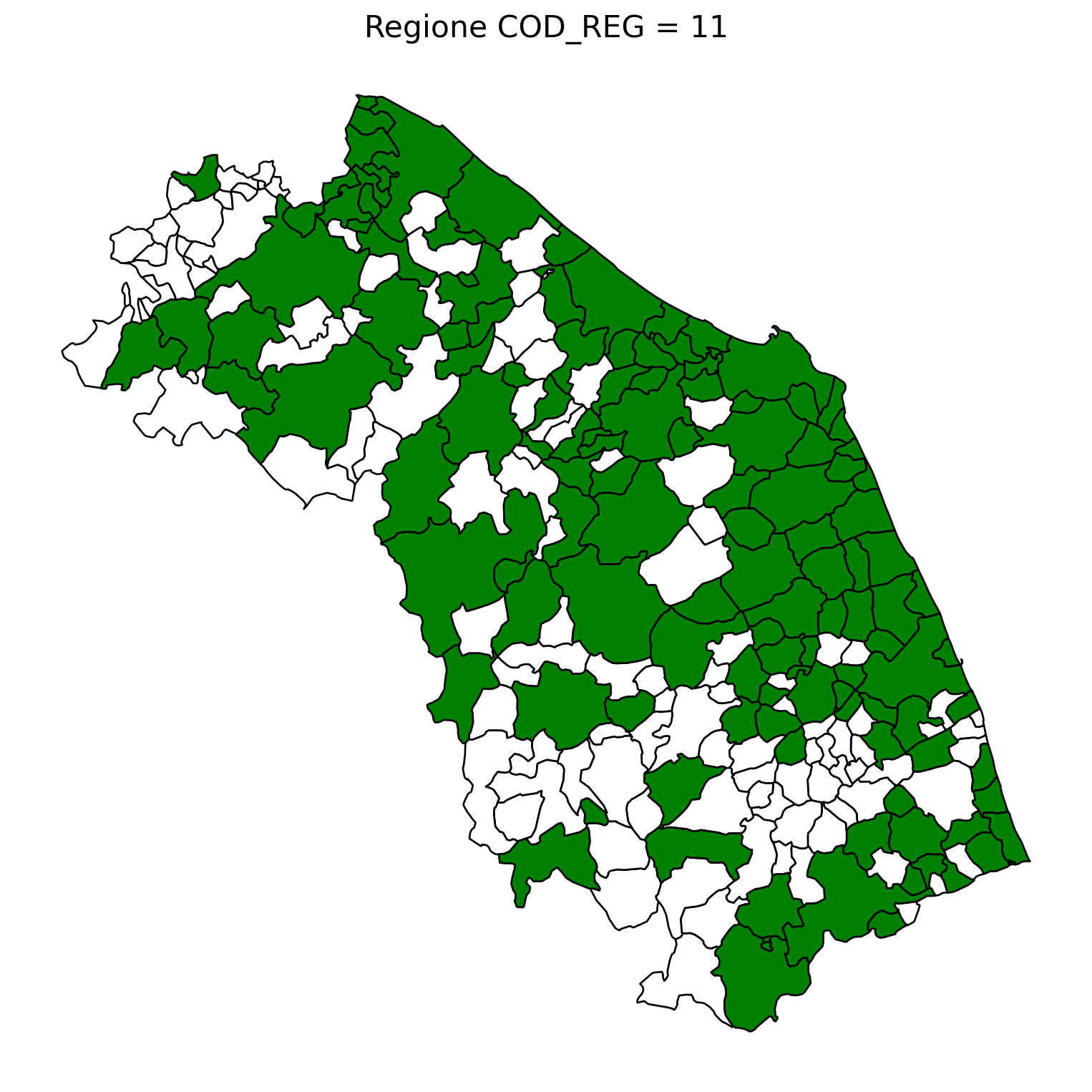
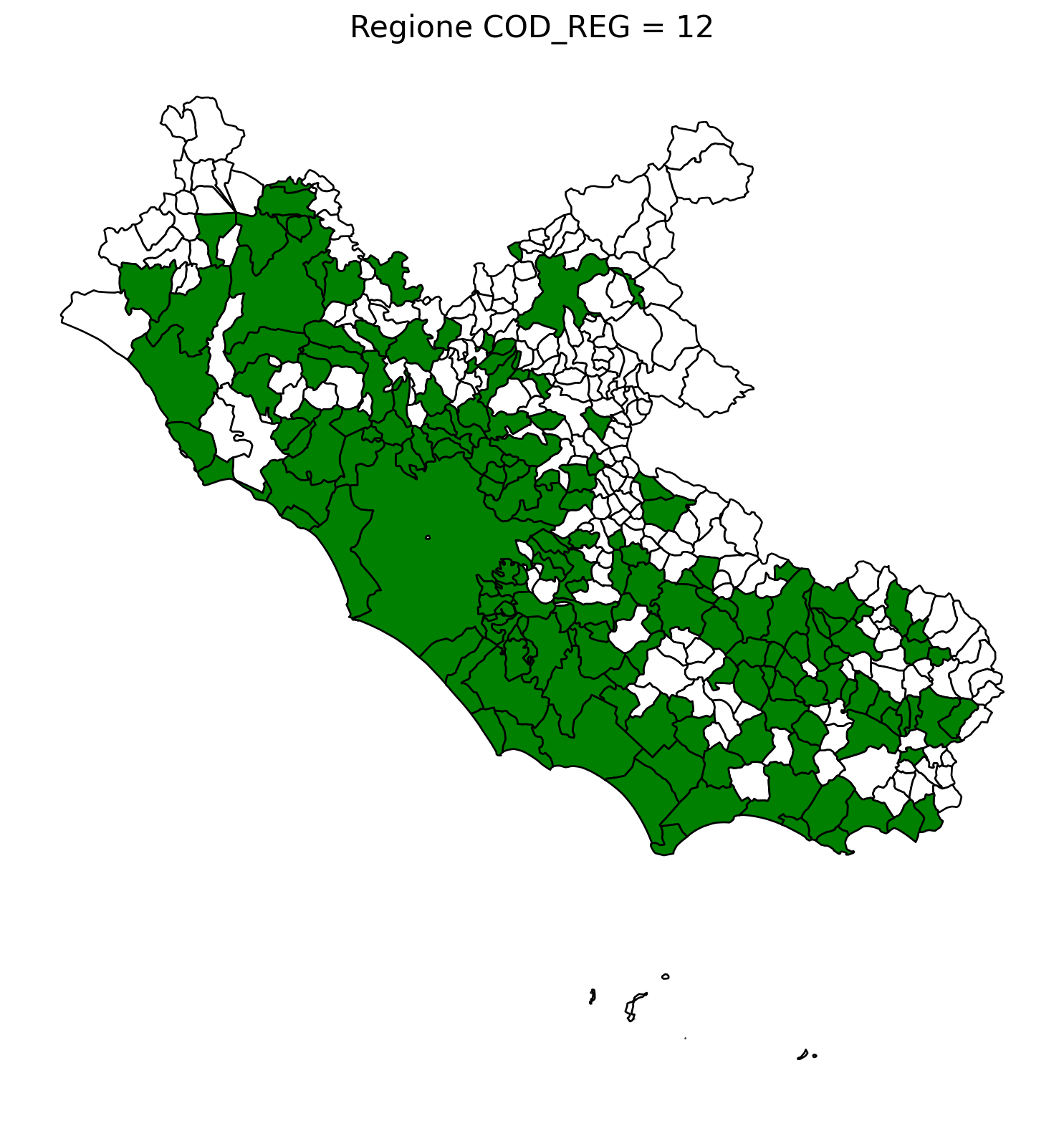
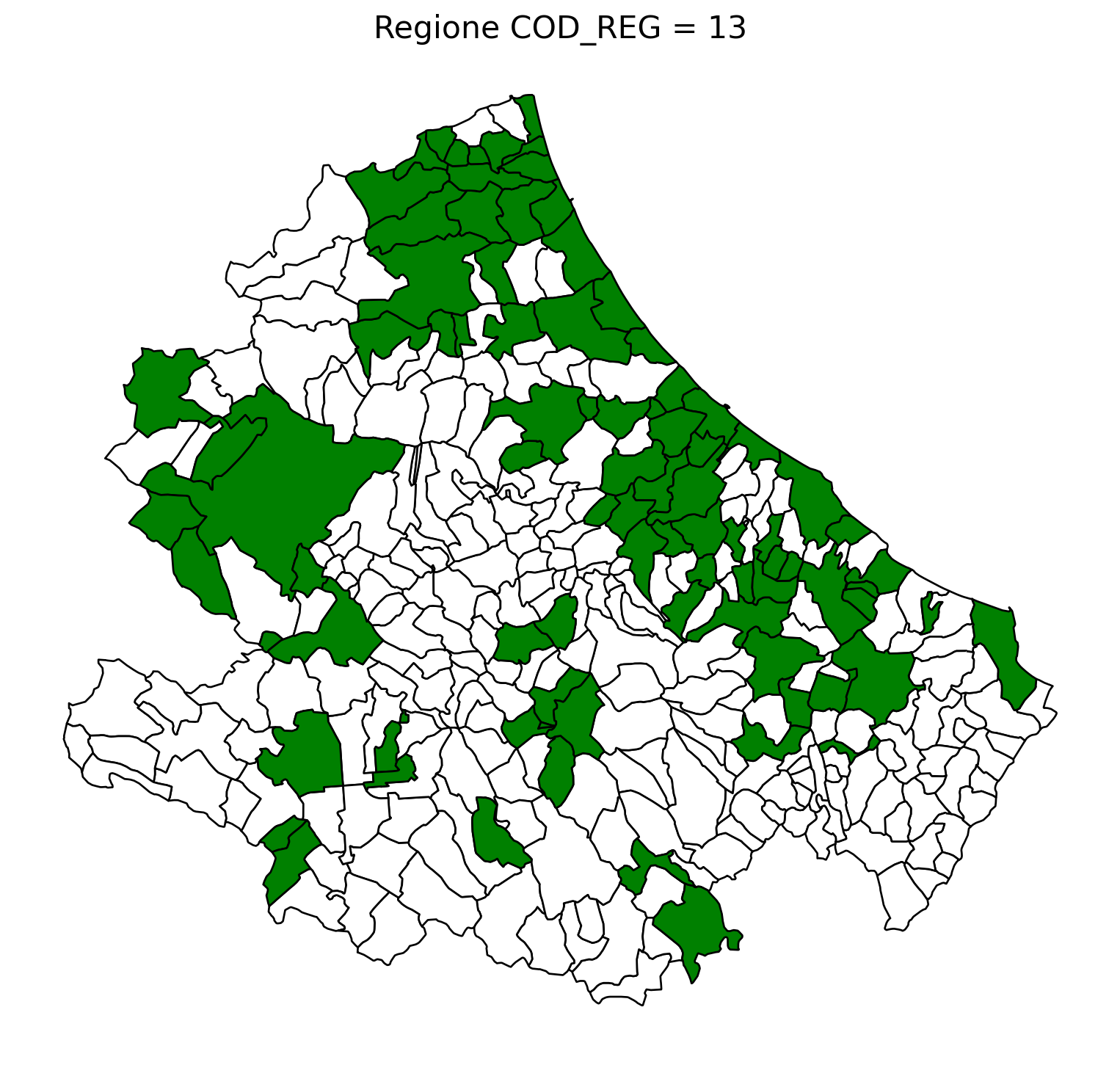
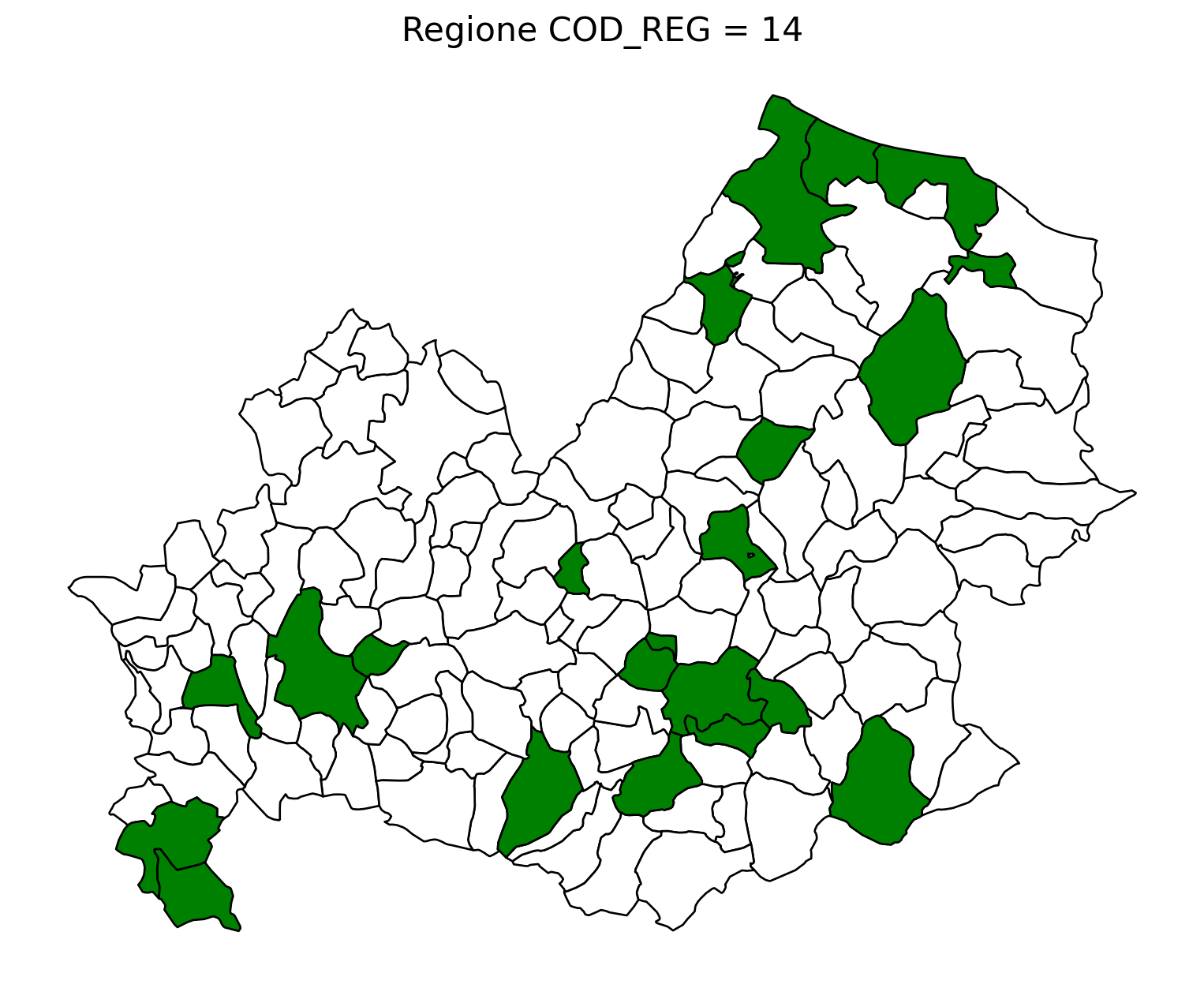
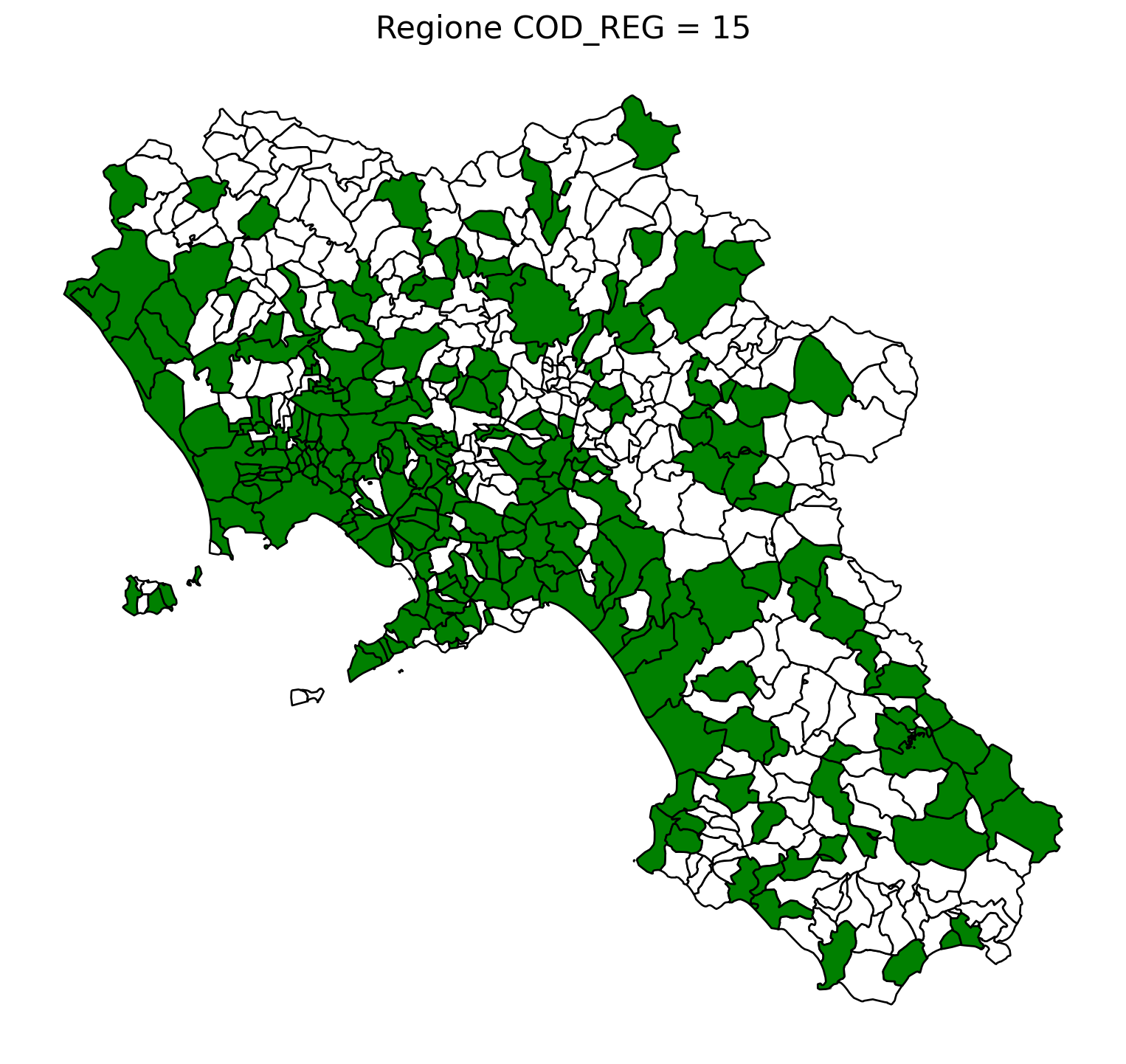
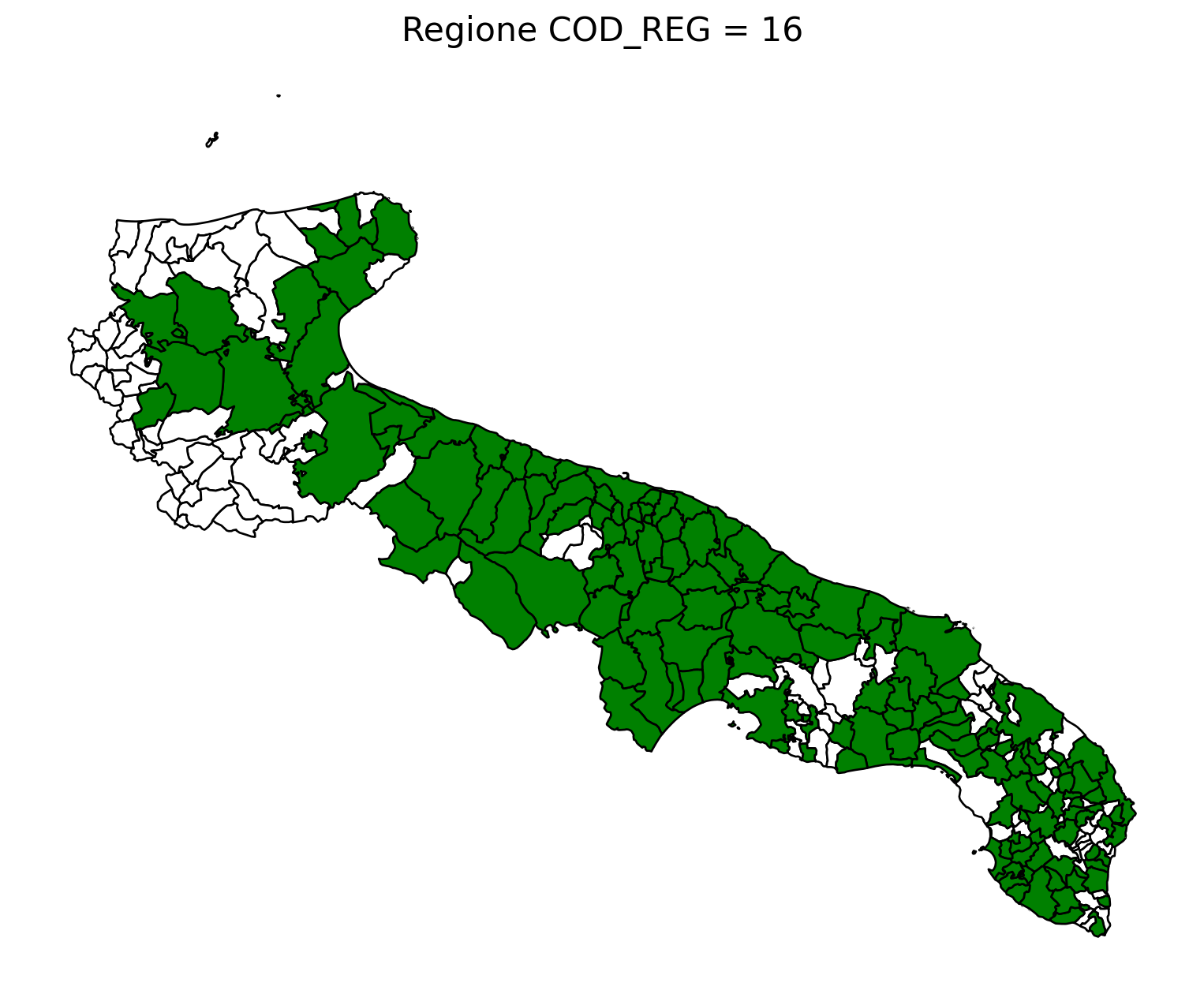
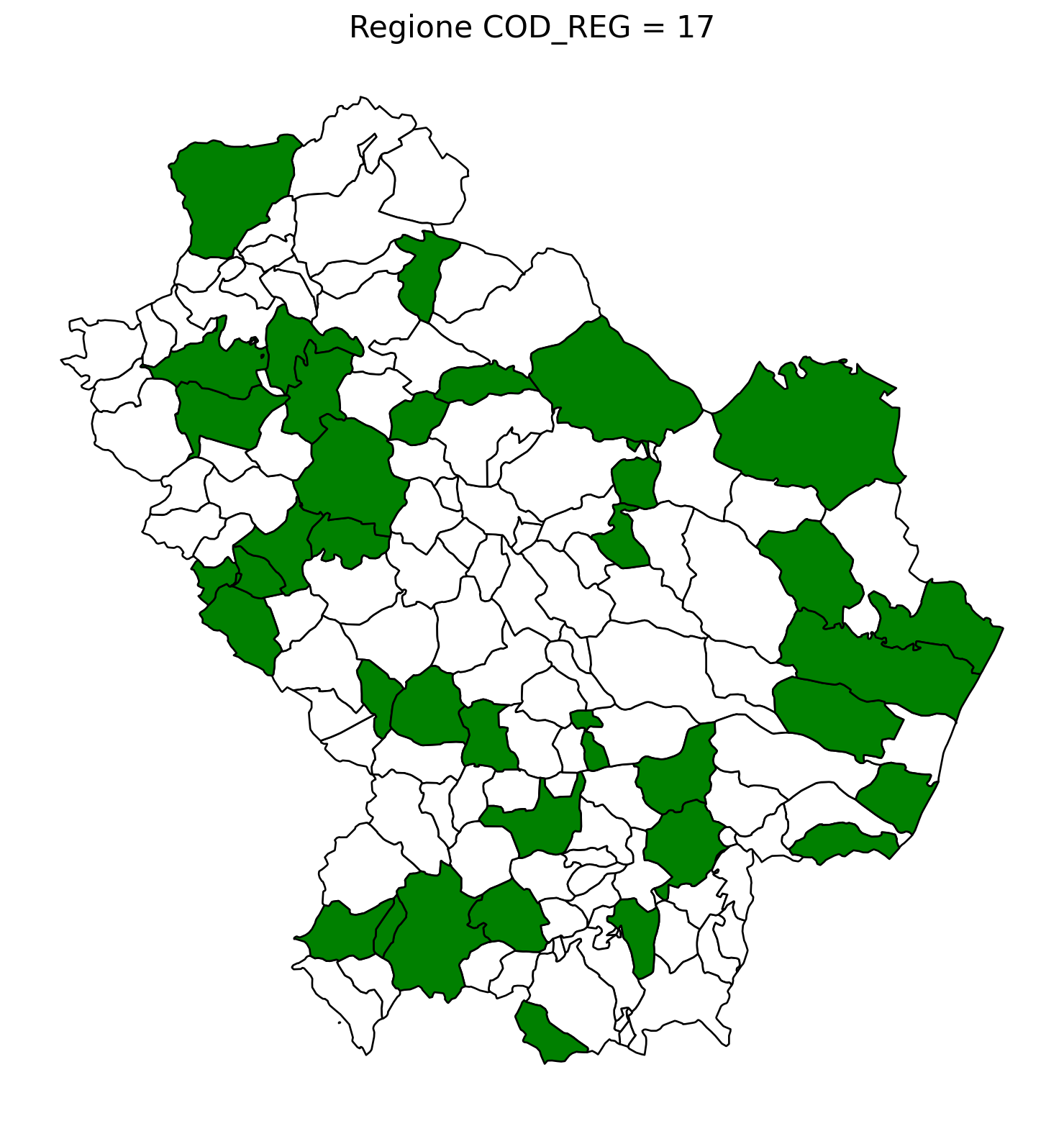
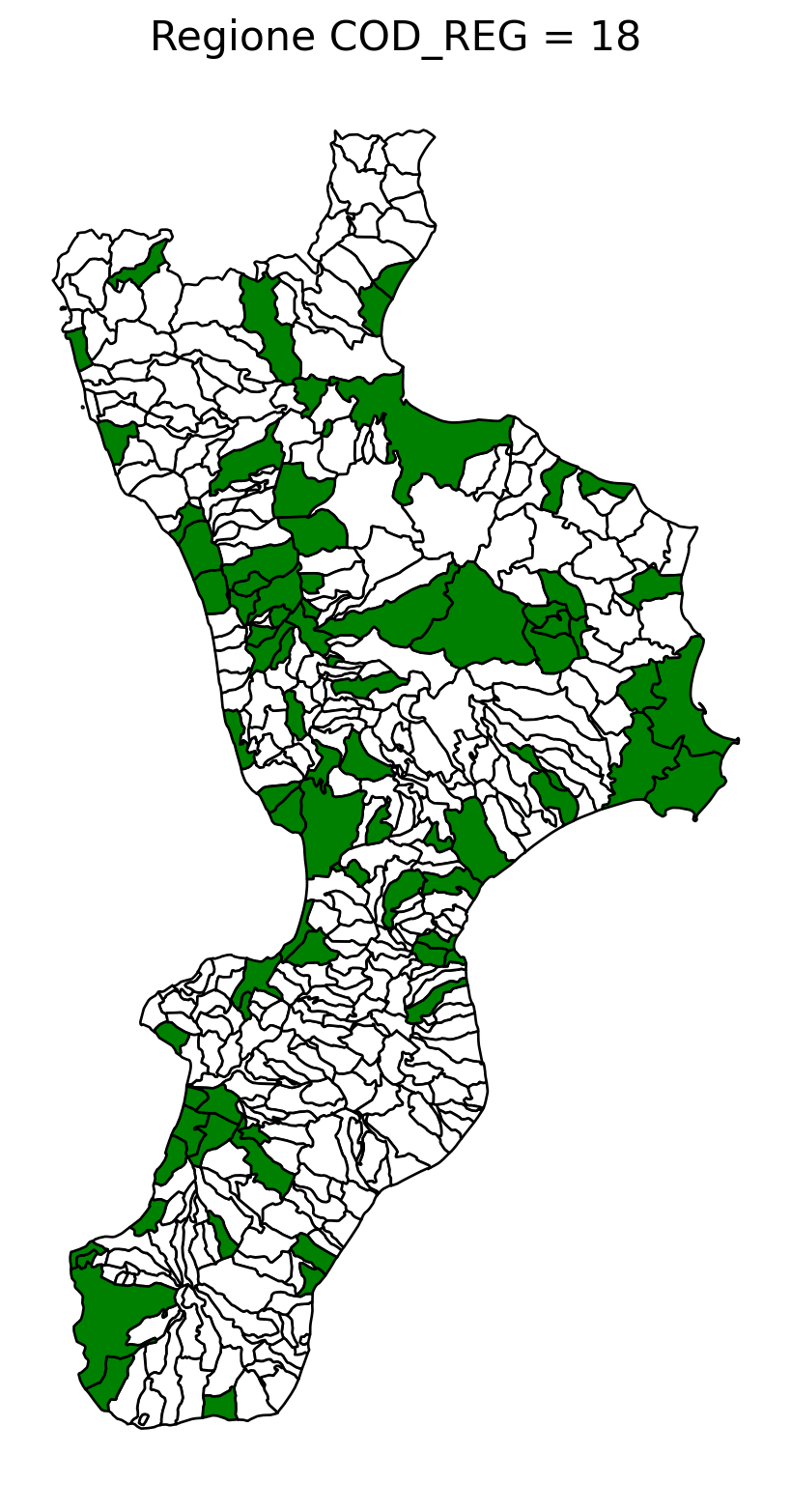
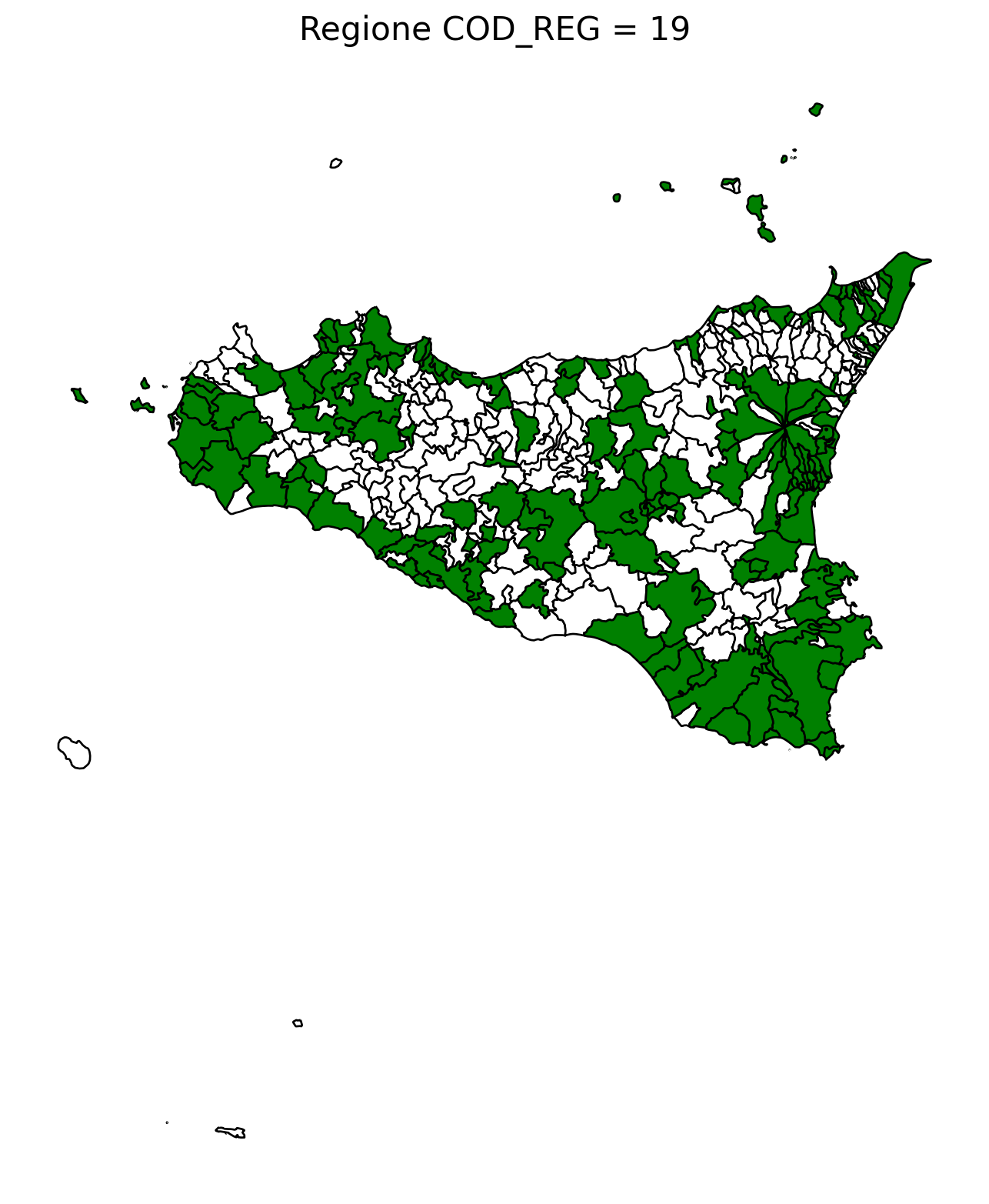
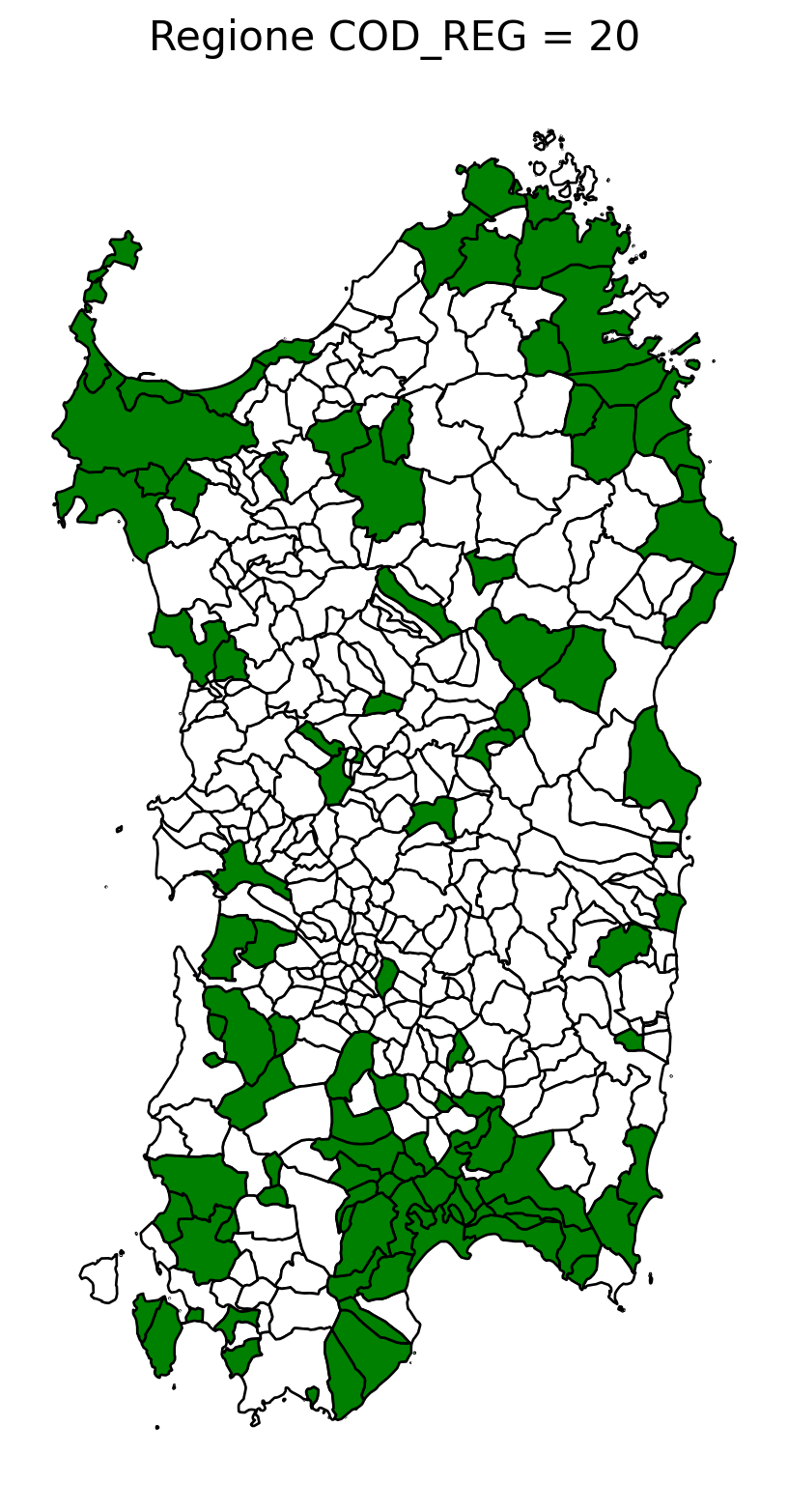
2.9 Inquiry
from itables import init_notebook_mode
init_notebook_mode(all_interactive=True)
from itables import show
show(
result2[['CUP', 'REGIONE', 'SIGLA_PROVINCIA', 'COMUNE','Data e ora presentazione domanda', 'Spese Ammesse (€)', 'Contributo Concesso (€)']],
layout={"top1": "searchPanes"},
searchPanes={"layout": "columns-3", "cascadePanes": True, "columns": [1,2]},
)
# result2.query('SIGLA_PROVINCIA=="ME"').sort_values(by='Data e ora presentazione domanda')| CUP | REGIONE | SIGLA_PROVINCIA | COMUNE | Data e ora presentazione domanda | Spese Ammesse (€) | Contributo Concesso (€) |
|---|---|---|---|---|---|---|
|
Loading ITables v2.2.3 from the init_notebook_mode cell...
(need help?) |